Оставить заявку
Для заказа и получения более подробной информации оставьте заявку, наш менеджер свяжется с Вами!
Нажимая на кнопку, вы даете согласие на обработку персональных данных и соглашаетесь c политикой конфиденциальности
Классификация гиперспектральных изображений: обзор
Hyperspectral Image Classification: A Review
Сарфараз Патан, Санджай Я. Азаде, Дипали В. Саване, Шабина Нааз Хан
Колледж компьютерных наук и информационных технологий им. д-ра Г.Я. Патрикара, Университет МГМ, Аурангабад, Махараштра, Индия
{sarfaraz.ip@gmail.com, dsawane@mgmu.ac.in}
Аннотация. Технология гиперспектральной съёмки (Hyperspectral imaging, HSI) используется для получения изображений объектов в многомерной форме; она объединяет технологии формирования изображений и спектроскопии для получения многомерных снимков. С помощью гиперспектральной съёмки можно изучать, анализировать внешние и внутренние характеристики любого объекта. Каждая характеристика объекта имеет уникальную спектральную сигнатуру (spectral signature), которая формируется на основе вариаций отражения или излучения материала объекта. Благодаря неразрушающему характеру гиперспектральной съёмки в настоящее время она проникает в такие отрасли, как производство продуктов питания, медицинская диагностика, точное земледелие (precision agriculture), фармацевтика, переработка отходов и экологический мониторинг. Мы рассмотрим различные методы классификации HSI, основанные на традиционных подходах, глубоком обучении (deep learning) и предварительно обученных классификаторах (pre‑trained classifiers).
Ключевые слова: глубокое обучение (deep learning) · свёрточная нейронная сеть (convolutional neural network, CNN) · спектральный (spectral) · пространственный (spatial).
1. Введение
Классификация (classification) — это фундаментальный метод обработки гиперспектральных изображений (HSI), который присваивает метку каждому пикселю на основе его свойств. Классификация гиперспектральных изображений — это метод, при котором похожие пиксели группируются в одну категорию. Классификация гиперспектральных изображений может выполняться либо на основе информации об отдельных пикселях, либо с использованием обучающих выборок. Изображения HSI классифицируются по данным пикселей как: основанные на знаниях (knowledge‑based), субпиксельные (sub‑pixel), по полям (per‑field), контекстуальные (contextual), с множеством классификаторов (multiple classifiers) или попиксельные (per‑pixel).
Техника классификации гиперспектральных изображений всё ещё сталкивается с рядом трудностей из-за сходства спектров, смешанных пикселей и многомерной природы гиперспектральных данных. Ниже приведены несколько проблем, требующих большего внимания:
- Вариативность пространственных спектральных данных (variability in spatial for spectral data). Спектральные данные гиперспектральных снимков изменяются в пространственном измерении из-за таких факторов, как атмосферные условия, сенсоры, состав и распределение наземных объектов, а также окружающая среда. В результате объект, соответствующий каждому пикселю, не является единым наземным объектом.
- Гиперспектральные данные обладают высокой размерностью (hyperspectral image data are highly dimensional). Размерность эквивалентной спектральной информации гиперспектральных изображений достигает сотен измерений, поскольку такие изображения создаются с использованием значений спектрального отражения, собранных авиационными или космическими спектрометрами в сотнях диапазонов.
- Недостаток размеченных образцов (missing samples with labels). В реальных приложениях получить гиперспектральные данные довольно просто, но получить информацию о метках, соответствующую изображениям, крайне сложно. Следовательно, классификация гиперспектральных изображений часто сталкивается с нехваткой размеченных образцов.
- Качество изображения (image calibre). Влияние фоновых элементов и шума во время съёмки гиперспектральных изображений существенно сказывается на качестве собранных данных. Точность классификации гиперспектральных изображений напрямую зависит от качества снимков.
В зависимости от способа обучения классификатора изображения HSI можно разделить на обучение с учителем (supervised), без учителя (unsupervised) и полуконтролируемое обучение (обучение с частичным привлечением учителя, semi‑supervised).
2. Методы машинного обучения (Machine Learning Methods)
2.1 Обучение с учителем (Supervised Machine Learning)
Обучение с учителем заключается в построении модели на основе размеченных обучающих данных для помощи в классификации или прогнозировании будущих данных. Образцы с учителем (supervised samples) — это те, для которых известен желаемый результат. Иными словами, разметка данных используется для направления поиска точного желаемого паттерна. Регрессия (regression) и классификация (classification) являются подразделами обучения с учителем.
Инструменты обучения с учителем (supervised learning tools) включают:
- Искусственные нейронные сети (Artificial Neural Networks)
- Деревья решений (Decision Trees)
- Случайный лес (Random Forest)
- Метод опорных векторов (Support Vector Machines, SVM)
- Метод k-ближайших соседей (k‑Nearest Neighbour, k‑NN)
- Логистическую регрессию (Logistic Regression)
- Наивный байесовский классификатор (Naive Bayes)
- Линейный дискриминантный анализ (Linear Discriminant Analysis)
2.2 Обучение без учителя (Unsupervised Machine Learning)
Обучение без учителя предполагает работу с немаркированными данными или неизвестными структурами данных. В отсутствие известной целевой переменной оно исследует структуру данных для получения значимой информации. С помощью обучения без учителя можно выполнять кластеризацию (clustering) и снижение размерности (dimensionality reduction).
Инструменты обучения без учителя (unsupervised learning tools) включают:
- Кластеризацию k-средних (k‑means clustering)
- Анализ независимых компонент (Independent Component Analysis, ICA)
- Метод главных компонент (Principal Component Analysis, PCA)
2.3 Полуконтролируемое обучение классификации (Semi‑supervised Machine Learning)
Полуконтролируемое обучение классификации (обучение с частичным привлечением учителя) обучает классификатор с использованием как размеченных, так и неразмеченных данных. Оно заполняет пробелы, оставленные отсутствием обучения с учителем и без учителя. В основе этого подхода лежит предположение, что размеченные и неразмеченные образцы имеют схожее распределение в пространстве признаков. Классификатор, построенный с использованием обоих типов выборок, обладает лучшей обобщающей способностью. Неразмеченные сегменты данных HSI содержат все свойства целевых данных, которые систематически собираются. Для повышения точности классификации полуконтролируемое обучение объединяет размеченные и неразмеченные данные.
Инструменты полуконтролируемого обучения (semi‑supervised learning tools) включают:
- Полуконтролируемый метод опорных векторов (Semi‑Supervised Support Vector Machines, SVM)
- Графовые полуконтролируемые методы (Graph Based Semi‑supervised)
- Самообучение (Self‑Training)
- Совместное обучение (Collaborative Training)
- Тройное обучение (Triple Training)
3. Представление гиперспектральных данных (Hyperspectral Depiction)
Гиперспектральные данные определяются образцом, объединяющим одномерные спектральные и двумерные пространственные признаки. Трёхмерный гиперкуб (hyper cube) математически выражается как
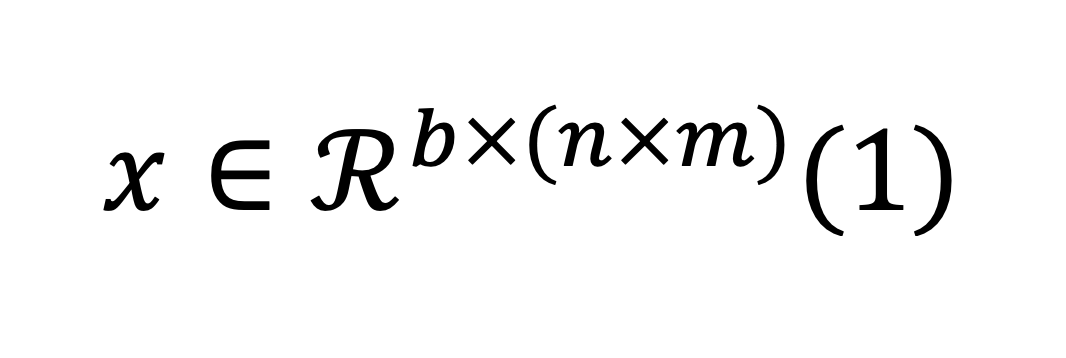
где: b — общее количество спектральных каналов (spectral bands);
n и m — пространственные компоненты (ширина и высота).
Представление гиперспектральных данных показано на рис. 1.
3.1 Спектральное представление (Spectral Depiction)
Спектральное представление — это процесс, при котором каждый массив пикселей изолируется от остальных пикселей, и обработка выполняется на основе спектральных сигнатур. Это означает, что пиксель характеризуется только в спектральном пространстве
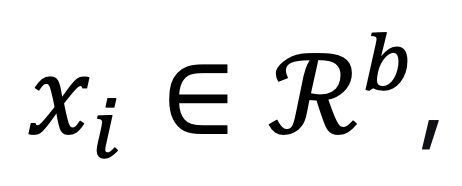
, где b — точное число спектральных каналов или соответствующих спектральных диапазонов, извлечённых с помощью методов снижения размерности (dimension reduction, DR). Для достижения лучшей разделимости классов без значительной потери полезной информации и избежания избыточности при обработке данных вместо исходных спектральных каналов рассматривается низкоразмерное представление HSI. Снижение размерности для спектрального представления данных HSI может быть с учителем (supervised) или без учителя (unsupervised).
Без учителя (Unsupervised)
Преобразование высокоразмерных данных HSI в низкоразмерные без использования меток классов. Примеры:
- Метод главных компонент (Principal Component Analysis, PCA)
- Локально-линейное встраивание (Locally Linear Embedding, LLE)
С учителем (Supervised)
Преобразование высокоразмерных данных HSI в низкоразмерные требует размеченных данных для изучения распределения. Примеры:
- Линейный дискриминантный анализ (Linear Discriminant Analysis, LDA)
- Локальный дискриминантный анализ Фишера (Local Fisher Discriminant Analysis, LFDA)
- Локальное дискриминантное встраивание (Local Discriminant Embedding)
- Непараметрическое взвешенное извлечение признаков (Nonparametric Weighted Feature Extraction)
3.2 Пространственное представление (Spatial Depiction)
Спектральное представление имеет ограничения, влияющие на точность классификации. Для их преодоления используется пространственное представление, извлекающее пространственные данные элементов изображения (пикселей). Здесь элементы изображения HSI в каждом диапазоне характеризуются в виде массива
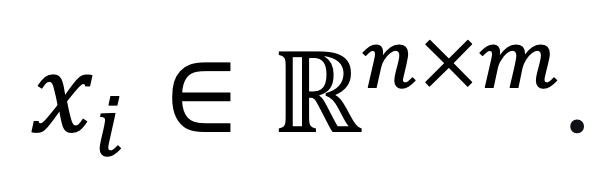
. Пространственные данные обладают большей корреляцией, поэтому вероятность того, что соседние пиксели принадлежат к одному классу, выше. В подходе спектрального представления данные соседних пикселей извлекаются с помощью ядра (kernel) или окна с центром в пикселе (pixel‑centric window).
Ниже приведены несколько способов извлечения пространственных данных из гиперкуба HSI.
Морфологические профили (Morphological Profiles)
Морфологические профили используются для извлечения геометрических свойств пространственных данных из изображений HSI. Существуют различные расширения морфологических профилей для анализа данных HSI:
- Расширенные морфологические профили (Extended Morphological Profiles)
- Морфологические профили с множественными структурообразующими элементами (Multiple Structure Element Morphological Profiles)
- Инвариантные профили признаков (Invariant Attributes Profiles)
Текстурные признаки (Texture Features)
Текстурные признаки предоставляют пространственные контекстные данные HSI. Их можно получить из текстуры изображения HSI. Некоторые методы извлечения текстурных признаков:
- Фильтр Габора (Gabor filter): используется для извлечения данных о различных масштабах и ориентациях.
- Локальный бинарный шаблон (Local Binary Pattern, LBP): используется для извлечения вращательно-инвариантной пространственной текстуры изображения.
- Серосеточная матрица совместной встречаемости (Gray Level Co‑occurrence Matrix, GLCM): используется для анализа пространственной вариативности HSI путём учёта относительных положений соседних пикселей.
Методы на основе глубоких нейронных сетей (DNN‑Based Methods)
Методы на основе глубоких нейронных сетей также используются для извлечения пространственных данных из HSI. В этом подходе пиксели рассматриваются как фрагменты изображения (image spot), а не как спектральные массивы. Пространственные данные HSI также могут быть получены комбинированием вышеуказанных методов. Например, классификатор HSI на основе рекуррентной нейронной сети (Recurrent Neural Network, RNN) может быть создан путём извлечения локальных пространственных последовательных признаков с использованием фильтра Габора и метода дифференциальных морфологических профилей (differential morphological profiles).
3.3 Совместное спектрально-пространственное представление (Spectral and Spatial Depiction)
В этом представлении используются как спектральная, так и пространственная информация. Такие методы обрабатывают вектор пикселя на основе спектральных свойств, одновременно учитывая пространственный контекст. Существует два основных подхода для одновременного использования спектральных и пространственных представлений HSI:
- Обработка трёхмерного гиперкуба HSI с сохранением реальной структуры и относительной информации.
- Объединение пространственной и спектральной информации.
Все эти представления HSI широко используются в литературе для классификации HSI. Большинство глубоких нейронных сетей для попиксельной классификации использовали спектральное представление HSI. Однако было предпринято множество попыток включить пространственную информацию, чтобы улучшить недостатки спектрального представления. В последнее время комбинированное использование пространственной и спектральной информации стало очень популярным и позволило повысить точность классификации.
4. Методы классификации гиперспектральных изображений (Hyperspectral Image Classification Methods)
4.1 Традиционные методы классификации HSI (Traditional HSI Classification Methods)
Метод опорных векторов (SVM), случайный лес (random forest) и другие являются традиционными методами классификации HSI. Из-за высокой размерности спектральных данных в классификации HSI часто возникает феномен Хьюза (Hughes phenomenon). Чтобы снизить размерность HSI, исследователи предложили ряд методов, включая PCA, PPCA и ICA. Снижение размерности позволяет успешно удалять избыточную информацию в данных HSI, улучшая извлечение признаков. При использовании традиционного подхода к классификации HSI выбор промежуточных параметров основан на предыдущем опыте, что приводит к недостаточной точности классификации и робастности.
4.2 Методы классификации HSI на основе глубокого обучения (Deep Learning HSI Classification Methods)
В отличие от традиционных подходов, методы глубокого обучения могут быстро изменять параметры модели с помощью градиентного спуска (gradient descent) и автоматически извлекать признаки из HSI. Наиболее популярные методы глубокого обучения перечислены ниже:
- Автокодировщики (Auto‑encoders)
- Глубокие сети доверия (Deep‑belief‑networks)
- Рекуррентные нейронные сети (Recurrent‑neural‑networks)
- Свёрточные нейронные сети (Convolutional‑neural‑networks)
4.3 Методы классификации HSI с использованием предварительно обученных моделей (Pre‑trained Model HSI Classification Methods)
Предварительно обученная модель (pre‑trained model) — это сохранённая сеть, которая уже была обучена на большом наборе данных, обычно для крупномасштабной задачи классификации изображений. Её можно либо использовать как есть, либо применить трансферное обучение (transfer learning) для адаптации к конкретной задаче. Ниже приведены несколько популярных предварительно обученных моделей:
- AlexNet
- VGG16
- GoogleNet
5. Направления для дальнейших исследований (Research Gap)
Ниже приведены области, в которых ещё предстоит проделать большую работу:
- В большинстве алгоритмов машинного обучения, используемых для анализа гиперспектральных данных, применяется ручное извлечение признаков (manual feature extraction), что значительно увеличивает время вычислений.
- Извлечение полезной информации из высокоразмерных гиперспектральных данных является сложной задачей.
- Классификация данных HSI, основанная только на спектральной информации, не даёт удовлетворительных результатов.
6. Заключение (Conclusions)
Наборы данных HSI являются огромными и многогранными, они требуют большой вычислительной мощности и памяти для обработки и классификации. Облачные вычисления (cloud computing) могут предложить инновационное решение для обработки таких данных, поскольку они обеспечивают большую масштабируемость, гибкость, устойчивость и экономическую эффективность. Разработка метода/модели классификации, объединяющей пространственную и спектральную информацию для классификации гиперспектральных изображений, позволит повысить точность классификации с использованием предварительно обученных методов глубокого обучения и внесёт значительный вклад в область классификации HSI. Большинство исследователей изучали классификацию данных HSI, фокусируясь на индивидуальной спектральной информации, а не на комбинации спектральной и пространственной информации, и разрабатывали методы классификации на основе спектральной информации с использованием: a) логистической регрессии (logistic regression), b) случайного леса (random forest classifier), c) метода опорных векторов (support vector machine algorithm), d) нейронных сетей (neural networks algorithm) и т.д. Однако классификация данных HSI только на основе спектральной информации не достигла удовлетворительных результатов.
25 марта / 2026