Оставить заявку
Для заказа и получения более подробной информации оставьте заявку, наш менеджер свяжется с Вами!
Нажимая на кнопку, вы даете согласие на обработку персональных данных и соглашаетесь c политикой конфиденциальности
Классификация гиперспектральных изображений: обзор
Доктор Г.Й. Патхрикар Колледж компьютерных наук и информационных технологий, Университет МГМ, Аурангабад, Махараштра, Индия
sarfaraz.ip@gmail.com, dsaWANE@mguu.ac.in
Аннотация. Технология гиперспектральной визуализации используется для получения изображений объектов в многомерной форме; она объединяет методы визуализации и спектроскопии для регистрации многомерных изображений. С помощью гиперспектральной визуализации (HSI) можно изучать внешние и внутренние характеристики любого объекта. Каждая характеристика любого объекта обладает уникальной спектральной сигнатурой, которая формируется на основе вариаций отражательной способности или излучения материала объекта. Благодаря неразрушающей природе гиперспектральной визуализации (HSI) в настоящее время она проникает в такие отрасли, как производство продуктов питания, медицинская диагностика, точное земледелие, фармацевтика, переработка отходов и экологический мониторинг. Мы рассмотрим различные методы классификации HSI, основанные на традиционных подходах, глубоком обучении и предварительно обученных классификаторах.
Ключевые слова: Глубокое обучение ⋅ Сверточные нейронные сети (CNN) ⋅ Спектральные ⋅Пространственные
1. Введение
Классификация — это фундаментальный метод обработки гиперспектральных изображений (HSI), который присваивает метку каждому пикселю на основе его свойств. Классификация гиперспектральных изображений — это методика, при которой схожие пиксели группируются в одну категорию. Классификация гиперспектральных изображений может выполняться либо на основе информации о пикселях, либо с использованием обучающих выборок. Изображения HSI классифицируются по типу пиксельных данных на: основанные на знаниях, субпиксельные, пополевые, контекстуальные, множественных классификаторах или попиксельные.
Техника классификации гиперспектральных изображений по-прежнему сталкивается с рядом трудностей из-за сходства между спектрами, смешанных пикселей и многомерной природы гиперспектральных данных. Ниже приведены несколько проблем, требующих большего внимания:
— Изменчивость пространственных спектральных данных. Спектральные данные гиперспектральных снимков изменяются в пространственном измерении в результате таких факторов, как атмосферные условия, сенсоры, состав и распределение наземных объектов, а также окружающая среда. Это приводит к тому, что наземный объект, соответствующий каждому пикселю, не является единственным. Гиперспектральные данные имеют высокую размерность. Размерность спектральной информации гиперспектральных изображений достигает сотен, поскольку гиперспектральные изображения создаются с использованием значений спектрального отражения, собранных бортовыми или космическими визуализирующими спектрометрами в сотнях каналов.
— Недостаток размеченных образцов. В реальных приложениях получить гиперспектральные данные довольно просто, но очень сложно получить информацию о метках (разметку), которая соответствовала бы изображениям. Следовательно, при классификации гиперспектральных изображений часто наблюдается нехватка размеченных образцов.
— Качество изображения. Влияние фоновых элементов и шума при получении гиперспектральных изображений существенно сказывается на качестве собранных данных. Точность классификации гиперспектральных изображений напрямую зависит от качества изображений.
В зависимости от модели обучения классификации изображения HSI можно разделить на обучение с учителем (Supervised), без учителя (Unsupervised) и полуавтоматическое (Semi‑supervised).
2. Методы машинного обучения
2.1 Обучение с учителем (Supervised Learning)
Обучение с учителем подразумевает построение модели на основе размеченных обучающих данных для облегчения классификации или прогнозирования будущих данных. Образцы с учителем — это образцы с известным желаемым выходом. Иными словами, разметка данных используется для направления поиска машиной точного желаемого шаблона. Регрессия и классификация являются подобластями обучения с учителем.
Инструменты обучения с учителем включают:
— Искусственные нейронные сети
— Деревья решений
— Случайный лес (Random Forest)
— Метод опорных векторов (Support Vector Machines)
— Метод k-ближайших соседей (k‑Nearest Neighbour)
— Логистическую регрессию (Logistic Regression)
— Наивный байесовский классификатор (Naive Bayes)
— Линейный дискриминантный анализ (Linear Discriminant Analysis)
2.2 Обучение без учителя (Unsupervised Learning)
Обучение без учителя подразумевает работу с немаркированными данными или данными с неизвестной структурой. При отсутствии известной целевой переменной оно исследует структуру данных для получения значимой информации. С помощью обучения без учителя можно выполнять кластеризацию и снижение размерности.
Инструменты обучения без учителя включают:
— Кластеризацию методом k-средних (k‑means)
— Анализ независимых компонентов (Independent Component Analysis, ICA)
— Метод главных компонентов (Principal Component Analysis, PCA)
2.3 Полуавтоматическое обучение (Semi‑supervised Learning)
Полуавтоматическая классификация обучает классификатор, используя как размеченные, так и неразмеченные данные. Она восполняет пробелы, оставленные отсутствием методов с учителем и без учителя. Этот подход основан на том, что размеченные и неразмеченные образцы находятся в одном и том же пространстве признаков. Согласно гипотезе близости (cluster assumption), классификатор, построенный с использованием обоих типов примеров, обладает лучшей обобщающей способностью. Неразмеченные сегменты данных HSI содержат все свойства целевых данных, которые были систематически зафиксированы. Для повышения точности классификации полуавтоматическое обучение объединяет размеченные данные с неразмеченными.
Инструменты полуавтоматического обучения включают:
— Полуавтоматические методы опорных векторов (Semi‑Supervised SVM)
— Графовые полуавтоматические методы (Graph Based Semi‑supervised)
— Самообучение (Self‑Training)
— Совместное обучение (Collaborative Training)
— Тройное обучение (Triple Training)
3. Представление гиперспектральных данных
Гиперспектральные данные определяются как объединение одномерных спектральных и двумерных пространственных признаков в одном образце. Трёхмерный гиперкуб математически выражается как
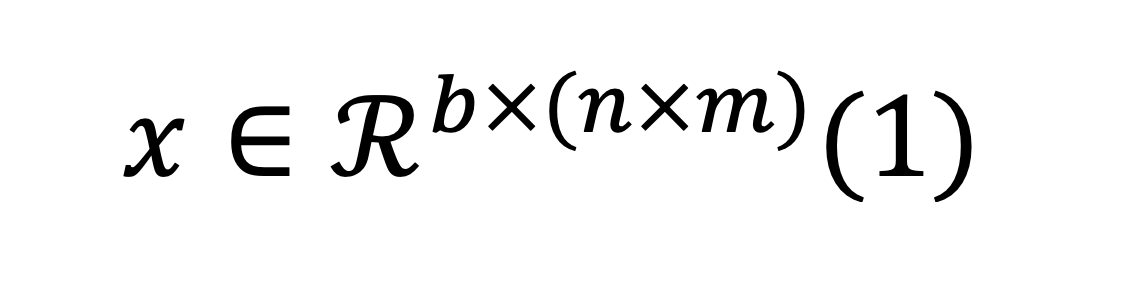
где:
b — общее количество спектральных каналов,
n и m— пространственные компоненты, соответственно ширина и высота.
Гиперспектральные данные представлены на рис. 1.
3.1 Спектральное представление (Spectral Depiction)
Спектральное представление — это процесс, при котором каждый массив пикселей изолируется от других пикселей, и обработка выполняется на основе спектральных сигнатур. Это означает, что пиксель характеризуется только в спектральном пространстве xi∈Rb,
, где
b обозначает точное количество спектральных каналов или подходящих спектральных диапазонов, которые извлекаются с помощью методов снижения размерности (DR). Чтобы добиться лучшей разделимости классов без значительной потери полезных данных и избежать избыточности, при обработке данных рассматривается низкоразмерное представление HSI вместо исходных спектральных каналов. Снижение размерности для спектрального представления данных HSI может быть как с учителем, так и без учителя.
<center>Рис. 1. Гиперспектральный куб.</center>
Методы без учителя (Unsupervised)
Преобразование высокоразмерных HSI-данных в низкоразмерные без использования меток классов. Ниже приведены несколько методов без учителя:
— Метод главных компонентов (PCA)
— Локально-линейное вложение (Locally Linear Embedding)
Методы с учителем (Supervised)
Преобразование высокоразмерных HSI-данных в низкоразмерные требует размеченных данных для изучения распределения данных. Ниже приведены несколько методов с учителем:
— Линейный дискриминантный анализ (Linear Discriminant Analysis, LDA)
— Локальный дискриминантный анализ Фишера (Local Fisher Discriminant Analysis, LFDA)
— Локальное дискриминантное вложение (Local Discriminant Embedding)
— Непараметрическое взвешенное извлечение признаков (Nonparametric weighted FE)
3.2 Пространственное представление (Spatial Depiction)
Спектральное представление имеет некоторые ограничения, влияющие на точность классификации; чтобы преодолеть это ограничение, используется подход пространственного представления, при котором извлекаются пространственные данные элементов изображения (пикселей) HSI. Здесь элементы HSI-изображения в каждом канале характеризуются в виде массива xi∈Rn×m.
. Пространственные данные обладают большей корреляцией, благодаря чему вероятность того, что соседние пиксели принадлежат одному классу, выше. В подходе спектрального представления используются данные соседних пикселей, и эти данные извлекаются с помощью ядра или центрированного на пикселе оконного метода.
Ниже приведены несколько способов извлечения пространственных данных из HSI-куба.
Морфологические профили (Morphological Profiles)
Морфологические профили используются для извлечения геометрических свойств пространственных данных из HSI-изображения. Существуют различные расширения морфологических профилей для анализа HSI-данных, такие как:
— Расширенные морфологические профили (Extended morphological profiles)
— Морфологические профили с множеством структурных элементов (Multiple Structure Element morphological profiles)
— Инвариантные атрибутные профили (Invariant attributes profiles)
Текстурные признаки (Texture Features)
Текстурные признаки предоставляют пространственные контекстные данные HSI. Их можно получить из текстуры HSI-изображения. Некоторые из методов, используемых для извлечения текстурных признаков:
— Фильтр Габора (Gabor filter): метод исследования текстуры на основе фильтра Габора используется для извлечения данных о различных масштабах и ориентациях.
— Локальный бинарный шаблон (Local Binary Pattern): метод исследования текстуры, используемый для вращательно-инвариантной пространственной текстуры изображения.
— Матрица совместной встречаемости уровней серого (Gray Level Co‑occurrence Matrix): изучает пространственную изменчивость HSI путём анализа относительных положений соседних пикселей.
Методы на основе глубоких нейронных сетей (DNN‑Based Methods)
Методы на основе глубоких нейронных сетей также используются для извлечения пространственных данных из HSI. В подходе на основе DNN пиксели рассматриваются как пятна (пространственные области) изображения, а не как спектральные массивы. Пространственные данные HSI также могут быть получены путём комбинирования вышеуказанных методов. Например, можно создать RNN-классификатор HSI, извлекая локальные пространственные последовательные признаки с помощью объединения фильтра Габора и дифференциальных морфологических профилей.
3.3 Совместное спектрально-пространственное представление (Spectral and Spatial Depiction)
В этом представлении одновременно используются как спектральная, так и пространственная информация данных. Эти методы обрабатывают вектор пикселя на основе спектральных свойств, принимая во внимание пространственный контекст. Ниже приведены два различных процесса, в которых одновременно используются спектральное и пространственное представление HSI:
— Обработка трёхмерного HSI-куба для сохранения реальной структуры и относительной информации.
— Объединение пространственной и спектральной информации.
Все эти виды представления HSI широко используются для классификации HSI в литературе. Большинство DNN для попиксельной классификации использовали спектральное представление HSI. Однако было предпринято множество попыток включить пространственную информацию, чтобы улучшить недостатки спектрального представления. В последнее время широкую популярность приобрело совместное использование пространственной и спектральной информации, которое повысило точность классификации.
4. Методы классификации гиперспектральных изображений
4.1 Традиционные методы классификации HSI
К традиционным методам классификации HSI относятся метод опорных векторов (SVM), случайный лес (Random Forest) и другие. В классификации HSI часто возникает феномен Хьюза (проклятие размерности) из-за высокой размерности спектра HSI. Чтобы снизить размерность HSI, исследователи предложили ряд методов, включая PCA, PPCA и ICA. Уменьшая избыточную информацию в HSI-данных, снижение размерности улучшает извлечение признаков HSI. При использовании классического подхода классификации HSI выбор промежуточных параметров основывается на предыдущем опыте, что приводит к недостаточной точности и робастности результатов классификации.
4.2 Методы классификации HSI на основе глубокого обучения
В отличие от традиционных подходов, методы глубокого обучения могут быстро изменять параметры модели через градиентный спуск и автоматически извлекать признаки из HSI. Ниже перечислены наиболее популярные методы глубокого обучения:
— Автокодировщики (Auto‑encoders)
— Глубокие сети доверия (Deep‑belief‑networks)
— Рекуррентные нейронные сети (Recurrent‑neural‑networks)
— Свёрточные нейронные сети (Convolutional‑neural‑networks)
4.3 Методы классификации HSI с использованием предварительно обученных моделей (Pre‑trained Model)
Предварительно обученная модель — это сохранённая сеть, которая уже прошла обучение на большом наборе данных, как правило, для крупной задачи классификации изображений. Модель либо используется как есть, либо к ней применяется трансферное обучение для адаптации к конкретной задаче. Ниже приведены несколько популярных предварительно обученных моделей:
— AlexNet
— VGG16
— GoogleNet
5. Пробелы в исследованиях (Research Gap)
Ниже приведены несколько областей, в которых ещё предстоит проделать значительную работу.
— В большинстве алгоритмов машинного обучения, используемых для анализа гиперспектральных данных, применяется ручное извлечение признаков, что значительно увеличивает время вычислений.
— Извлечение полезной информации из высокоразмерных гиперспектральных данных является сложной задачей.
— Классификация HSI-данных, основанная только на учёте спектральной информации, не даёт удовлетворительных результатов.
6. Выводы
Наборы данных HSI являются огромными и многогранными, они требуют больших вычислительных мощностей и памяти для обработки и классификации. Облачные вычисления могут предложить инновационное решение для обработки таких данных, поскольку они обеспечивают большую масштабируемость, гибкость, устойчивость и экономическую эффективность. Разработка методов/моделей классификации, объединяющих пространственную и спектральную информацию для классификации гиперспектральных изображений, позволит повысить точность классификации с использованием предварительно обученных методов глубокого обучения и внесёт значительный вклад в область классификации HSI. Большинство исследователей изучали классификацию HSI-данных, сосредотачиваясь на отдельной спектральной информации, а не на объединении спектральной и пространственной информации; они создавали методы классификации по спектральной информации с использованием: a) логистической регрессии, b) классификатора случайного леса, c) метода опорных векторов, d) нейронных сетей и т.д. Однако классификация HSI-данных, основанная только на спектральной информации, не даёт удовлетворительных результатов классификации.
Лицензия: Данная глава распространяется на условиях лицензии Creative Commons Attribution-NonCommercial 4.0 International (http://creativecommons.org/licenses/by-nc/4.0/), которая разрешает любое некоммерческое использование, совместное использование, адаптацию, распространение и воспроизведение на любом носителе или в любом формате при условии надлежащего цитирования первоначального автора (авторов), источника и указания ссылки на лицензию Creative Commons, а также указания, были ли внесены изменения.
04 мая / 2026