Оставить заявку
Для заказа и получения более подробной информации оставьте заявку, наш менеджер свяжется с Вами!
Нажимая на кнопку, вы даете согласие на обработку персональных данных и соглашаетесь c политикой конфиденциальности
Раннее выявление вирусных заболеваний растений с помощью гиперспектральной съёмки и глубокого обучения
Canh Nguyen ¹,²; Vasit Sagan ¹,²,*; Matthew Maimaitiyiming ³; Maitiniyazi Maimaitijiang ¹,²; Sourav Bhadra ¹,² and Misha T. Kwasniewski ³,⁴
- Geospatial Institute, Saint Louis University, Saint Louis, MO 63108, USA;
- canh.nguyen@slu.edu (C.N.); mason.maimaitijiang@slu.edu (M.M.); sourav.bhadra@slu.edu (S.B.)
- Department of Earth and Atmospheric Sciences, Saint Louis University, St. Louis, MO 63108, USA
- Division of Food Sciences, University of Missouri, Columbia, MO 65211, USA;
- matt.maimaitiyiming@slu.edu (M.M.); mtk5407@psu.edu (M.T.K.)
- Department of Food Sciences, The Pennsylvania State University, University Park, PA 16802, USA
Correspondence: vasit.sagan@slu.edu
Аннотация:
Раннее выявление вирусных заболеваний виноградной лозы имеет решающее значение для своевременного вмешательства, чтобы предотвратить распространение болезни на весь виноградник. Гиперспектральная дистанционная съёмка потенциально позволяет выявлять и количественно оценивать вирусные заболевания неразрушающим способом.
В данном исследовании использовалась гиперспектральная съёмка для выявления и классификации виноградных лоз, заражённых недавно обнаруженным ДНК-вирусом — вирусом мраморности листьев винограда (GVCV) — на ранних, бессимптомных стадиях.
Эксперимент был проведён на тестовом участке в Научно-исследовательском центре South Farm (Колумбия, штат Миссури, США, координаты: 38,92° с. ш., 92,28° з. д.). Были взяты две группы виноградных лоз: здоровые и заражённые вирусом GVCV, при этом остальные условия были контролируемыми.
Изображения каждой лозы были получены с помощью гиперспектрального датчика SPECIM IQ с диапазоном 400–1000 нм (Оулу, Финляндия). Гиперспектральные изображения были откалиброваны и предварительно обработаны для выделения только пикселей, соответствующих виноградной лозе.
С помощью статистического подхода были выявлены различия в спектрах отражения между здоровыми лозами и лозами, заражёнными вирусом GVCV. Были разработаны индексы растительности, специфичные для заболеваний (VIs), и проанализирована их значимость для классификации.
Классификация по пикселям (спектральные признаки) проводилась параллельно с классификацией по изображениям (совместные пространственно-спектральные признаки) в рамках архитектуры, включающей глубокое обучение и традиционные методы машинного обучения.
Результаты исследования показали следующее: ключевые диапазоны волн, позволяющие проводить дифференциацию: диапазон 900–940 нм в ближней инфракрасной области (NIR) для лоз через 30 дней после посева (DAS) и весь видимый диапазон (VIS) 400–700 нм для лоз через 90 дней после посева (DAS); Наиболее информативными индексами оказались: нормализованный индекс феофитинизации (NPQI), индекс соотношения флуоресценции 1 (FRI1), индекс отражения, характеризующий старение растений (PSRI), индекс антоцианов (AntGitelson) и показатели стресса, вызванного недостатком воды, и температуры кроны (WSCT); Метод опорных векторов (SVM) показал эффективность при классификации по индексам растительности (VI) в пространствах с меньшим количеством признаков, в то время как классификатор RF продемонстрировал лучшие результаты при классификации по пикселям и изображениям в пространствах с большим количеством признаков; Автоматизированный экстрактор признаков на основе трёхмерной свёрточной нейронной сети (3D-CNN) показал многообещающие результаты по сравнению с двухмерной свёрточной нейронной сетью (2D-CNN) при извлечении признаков из гиперспектральных «кубов данных» с ограниченным количеством образцов.
Введение
Изменение климата, непредсказуемые выпадения осадков и колебания температуры создают оптимальные условия для размножения, выживания и распространения вирусов [1].
В связи с этим надёжная и точная идентификация заболеваний растений на ранней стадии крайне необходима для решения актуальных задач в сельском хозяйстве. Существующие методы диагностики на месте (in situ) традиционно представляют собой последовательность этапов: визуальный осмотр посевов в поле на предмет уже явно заметных признаков заболевания; проведение интенсивных диагностических тестов в лабораторных условиях.
Реакция растений на появление вредителей и болезней в полевых условиях неоднородна [2]: обычно заболевание начинается с небольшого участка листвы, а затем распространяется на всё поле.
Методы ручного выявления заболеваний обладают существенными недостатками: требуют много времени; трудоёмкое;не подходят для масштабного раннего вмешательства.
Инновационные методы ведения сельского хозяйства с применением высокоточных технологий способны восполнить этот пробел. Они позволяют: выявлять предварительные (до появления визуальных симптомов) признаки заболеваний; определять поражённые участки; предотвращать дальнейшее распространение болезни.
Вирус мраморности листьев винограда (GVCV) был недавно обнаружен — это первый ДНК-вирус, выявленный у виноградных лоз. Он представляет собой новый вид рода Badnavirus, относящийся к семейству Calimorividae.
Болезнь, вызываемая GVCV, представляет серьёзную угрозу для устойчивого роста и урожайности виноградных лоз в Среднем Западе США 3.
Диагностические симптомы заболевания можно наблюдать на молодых побегах: края листьев расщепляются и становятся морщинистыми; главные и второстепенные жилки листьев выглядят полупрозрачными; появляются зигзагообразные междоузлия, которые со временем становятся заметными.
Инфицированные листья часто деформируются и уменьшаются в размере, что приводит к: снижению размера лозы; менее плотной кроне по сравнению со здоровыми лозами.
У сильно поражённых лоз наблюдаются следующие признаки: уменьшение размера гроздей; неправильная форма гроздей; нарушение структуры ягод.
Некоторые распространённые сорта винограда, восприимчивые к GVCV: Шардоне (Chardonnay); Шардонел (Chardonel); Видаль Блан (Vidal Blanc).
Сорта, устойчивые к вирусу: Нортон (Norton); Шанбурсин (Chanbourcin).
Сорта, толерантные к вирусу (при заражении проявляют лишь слабые симптомы): Виньоль (Vignoles); Траминетт (Traminette).
Единственный метод, позволяющий достоверно подтвердить наличие вируса GVCV на лозе, — это полимеразная цепная реакция (ПЦР), представляющая собой молекулярный тест 3.
Среди пассивных методов дистанционного зондирования, измеряющих солнечное излучение, отражённое от объектов, гиперспектральная съёмка (HSI) демонстрирует большой потенциал как неинвазивный и неразрушающий инструмент мониторинга биотического и абиотического стресса растений [4]. Этот метод фиксирует и сохраняет спектроскопическую информацию об объекте в виде спектрального куба, который содержит пространственные данные и сотни смежных длин волн в третьем измерении.
Гиперспектральные изображения открывают широкие возможности для раннего выявления заболеваний растений, позволяя обнаруживать довизуальные индикаторы посредством незначительных изменений спектральной отражательной способности, вызванных поглощением или отражением излучения.
Насколько нам известно, исследований, посвящённых защитной реакции виноградной лозы на вирус GVCV, до сих пор не проводилось. Поэтому мы предположили, что после заражения вирусом растение‑хозяин активирует механизм защиты, аналогичный тому, что наблюдается у других видов.
Биохимические и биофизические свойства поражённого растения начинают изменяться, формируя спектральную сигнатуру, отличающуюся от сигнатуры здоровых растений. Такие изменения могут быть зафиксированы дистанционными спектральными датчиками.
Например, на ранних стадиях заболевания визуальные симптомы на инфицированных листьях отсутствуют, однако начинается корректировка ряда физиологических параметров, в том числе:
● закрытие устьиц;
● снижение транспирации;
● уменьшение скорости фотосинтеза;
● повышение флуоресценции и тепловыделения [5].
Тепловые свойства поражённых листьев аномально изменяются — главным образом из‑за колебаний содержания воды. Эти изменения также можно выявить на ранних стадиях заражения [6, 7].
На более поздних стадиях содержание хлорофилла в листьях может снижаться из‑за некротических или хлоротических поражений. На листьях появляются инфицированные участки с эффектом побурения, вызванным старением растения [8]. Изменённые пигменты могут быть зафиксированы в видимой (VIS) и ближней инфракрасной (NIR) областях спектра.
Структурные характеристики, такие как плотность кроны и площадь листьев инфицированного растения, могут уменьшаться, что также влияет на NIR‑область спектра [9, 10].
Интенсивные исследования в области выявления болезней растений задействуют гиперспектральную съёмку для раннего обнаружения патогенов и заболеваний на различных пространственных, спектральных и временных масштабах.
В качестве примеров можно привести использование отражательной способности листьев для различения изменений сигнала, вызванных листовыми патогенами, у сахарной свёклы [11–13]; пшеницы [14, 15]; яблони [16]; ячменя [17, 18]; томата [19].
На уровне полей гиперспектральные изображения полезны для раннего выявления: токсинообразующих грибов на кукурузе [20]; жёлтой ржавчины на пшенице [21]; оранжевой ржавчины на сахарном тростнике [22]; болезней табака [23].
Успешность методов на основе гиперспектральной съёмки также подтверждается:улучшенным разграничением весьма сложных и уникальных паттернов почвенных заболеваний сахарной свёклы [24]; повышенной точностью классификации уровней заражения мучнистой росой виноградных лоз [25].
Благодаря последним достижениям в области беспилотных летательных аппаратов (БПЛА) воздушные снимки стали использовать для мониторинга сорняков и выявления болезней [26–29].
В более узком обзоре точного виноградарства [30] изучалась устойчивость трёх сортов виноградной лозы к Plasmopara viticola с помощью гиперспектрального датчика.
Другие исследования [27, 28] позволили: различить симптомы Flavescence dorée у двух сортов красной и белой виноградной лозы; в последующей работе — разграничить два заболевания (Flavescence dorée и болезнь стволов виноградной лозы) у сортов красного винограда.
С помощью гиперспектрального дистанционного зондирования на разных сортах винограда также рано выявлялись такие болезни, как: листовая скрученность [31, 32]; полосатость листьев [29]; пожелтение; эска [33].
Таким образом, применение технологии гиперспектральной съёмки можно разделить на следующие категории:
- Раннее выявление заболеваний и их симптомов.
- Различение разных заболеваний.
- Разделение паттернов заболеваний.
- Количественная оценка степени тяжести заболевания.
При обработке гиперспектральных изображений растительности часто возникает проблема дисбаланса: с одной стороны — ограниченное количество обучающих образцов, с другой — высокая размерность данных изображений. Это явление известно как феномен Хьюза [34].
В сообществе специалистов по дистанционному зондированию предложены различные подходы к решению этой проблемы.
Преобладающий метод заключается в извлечении исключительно спектральной информации из каждого пикселя изображения. Этот пиксельный подход предполагает, что каждый пиксель представляет собой одномерный вектор спектров отражения и соответствующим образом маркируется целевым значением.
Обычно это включает:
- Снижение размерности данных — в качестве этапа предварительной обработки.
- Основные задачи моделирования (например, классификацию).
Для преобразования спектральных данных в управляемые низкоразмерные данные наиболее широко применяются два подхода:
- Выбор спектральных диапазонов — используется для отбора дискретного числа ключевых длин волн в различных участках спектра с целью расчёта репрезентативных индексов (например, вегетационных индексов) [21, 35, 36]. При этом подход с выбором диапазонов позволяет сохранить максимально возможный объём спектральной информации.
- Преобразование данных — использует трансформацию для сжатия данных до нового оптимального размера.
Среди распространённых методов извлечения гиперспектральных данных, применяемых в патологических исследованиях, можно выделить: анализ главных компонент (PCA) [37]; производный анализ [38]; вейвлет‑методы; корреляционные графики [39].
Следует отметить, что хотя пиксельные методы позволяют работать с малым объёмом обучающих образцов, они одновременно игнорируют пространственную информацию [40].
В качестве альтернативы можно обрабатывать данные гиперспектральных изображений на уровне всего изображения, извлекая либо только пространственное представление, либо совместную пространственно‑спектральную информацию.
Если учитывать только пространственные характеристики (например, при изучении структурных и морфологических особенностей), будут выделены пространственные паттерны между соседними пикселями по отношению к текущему пикселю на гиперспектральном изображении.
Для автоматического получения высокоуровневых пространственных паттернов применяются методы машинного зрения — в частности, двумерная свёрточная нейронная сеть (CNN) с входными данными в виде фрагмента размером p × p пикселей.
Доказано, что совместное извлечение пространственных и спектральных характеристик существенно повышает эффективность модели.
Использовать пространственно‑спектральные характеристики можно двумя способами:
- Раздельное извлечение пространственных характеристик — например, с помощью одномерной (1D‑CNN) или двумерной (2D‑CNN) свёрточной нейронной сети [41, 42], а затем объединение данных со спектральным экстрактором (например, с использованием рекуррентной нейронной сети (RNN) или сети долгой краткосрочной памяти (LSTM) [42, 43]).
- Использование трёхмерных фрагментов (p × p × b), включающих:
○ p × p — пространственные соседние пиксели;
○ b — спектральные диапазоны.
- Это позволяет в полной мере выявить значимые различительные паттерны в гиперспектральных кубических данных.
Несмотря на успехи в разработке архитектуры 3D‑CNN, лишь немногие исследования применяли этот подход для гиперспектрального зондирования при выявлении болезней растений [44]. Ограничения связаны с малым объёмом обучающих наборов данных для моделей на основе гиперспектральных изображений, тогда как глубокое обучение требует очень большого количества размеченных данных.
В данном исследовании мы попытались использовать архитектуру 3D‑CNN в качестве экстрактора признаков, чтобы в полной мере задействовать совместную пространственно‑спектральную корреляционную информацию. Затем модель была обучена с применением традиционных методов машинного обучения. Цель — снизить влияние проблемы малого объёма обучающих выборок при классификации на уровне изображений.
В задачах классификации традиционные алгоритмы машинного обучения — метод опорных векторов (SVM) и классификатор «случайный лес» (RF) [45] — привлекли значительное внимание исследователей в области дистанционного зондирования благодаря своей универсальности и тому, что они не требуют предположений о распределении данных [26, 46–48].
Алгоритм SVM представляет собой метод обучения с учителем, цель которого — максимизировать запас(margin), то есть расстояние между разделяющей гиперплоскостью (границей решения) и ближайшими к ней обучающими примерами (опорными векторами).
Классификатор RF — это ансамблевый метод, объединяющий несколько классификаторов (в данном исследовании — деревья решений) в единый метаклассификатор. Такой подход обеспечивает: более высокую надёжность; лучшую обобщающую способность по сравнению с отдельными классификаторами.
При работе с классификатором RF метка класса определяется по принципу большинства или множественного голосования: выбирается класс, получивший наибольшее число голосов от отдельных деревьев решений.
На небольших обучающих выборках традиционные алгоритмы машинного обучения обычно демонстрируют хорошие результаты. Однако при сравнении с методами глубокого обучения, применяемыми к крупным наборам данных, их точность может: оставаться на том же уровне; снижаться [49].
По этой причине мы адаптировали свёрточные нейронные сети для работы с изображениями и использовали алгоритмы SVM и RF в качестве классификаторов, заменив ими полносвязные слои.
Общая цель текущего исследования заключалась в изучении возможностей гиперспектральной съёмки для раннего выявления довизуальных заражений вирусом (GVCV) у лоз сорта Шардонель.
Мы ставили перед собой следующие основные задачи:
- Различить спектры отражения у здоровых лоз и лоз, поражённых вирусом GVCV, на различных стадиях развития инфекции — с использованием статистического теста.
- Провести разведочный анализ для определения значимости вегетационных индексов, специфичных для данного заболевания.
- Классифицировать здоровые лозы и лозы, поражённые вирусом GVCV, с помощью трёх подходов: на основе вегетационных индексов; на основе пиксельного анализа; на основе анализа изображений.
При этом использовались как вручную разработанные, так и автоматизированные методы извлечения признаков с применением глубокого обучения, а также методы машинного обучения.
2. Материалы и методы
2.1. Область исследования и сбор данных
Эксперимент был проведён возле Научно-исследовательского центра Южной фермы Университета Миссури, Колумбия, штат Миссури (координаты: 38.92° с. ш., –92.28° з. д.) (рис. 1а).
Согласно данным местной метеостанции (http://agebb.missouri.edu/weather/stations/boone/index.htm), средняя температура и количество осадков в период проведения эксперимента летом 2019 года составили 21,83 °C и 2,9 мм соответственно (рис. 1b).
Для эксперимента был выбран только сорт винограда «Шардонель» (Chardonel) ввиду его восприимчивости к вирусу GVCV. Виноградные лозы были разделены на две группы:
● здоровая группа (контрольная);
● группа инфицированных лоз, заражённых вирусом GVCV.
При этом все остальные экспериментальные факторы были идентичны для обеих групп — условия были максимально схожими.
Легенда к графику (рис. 1b):
● синие столбики — количество осадков (мм);
● сплошная красная линия — средняя температура (°C);
● пунктирная чёрная линия — максимальная температура (°C);
● пунктирная жёлтая линия — минимальная температура (°C).
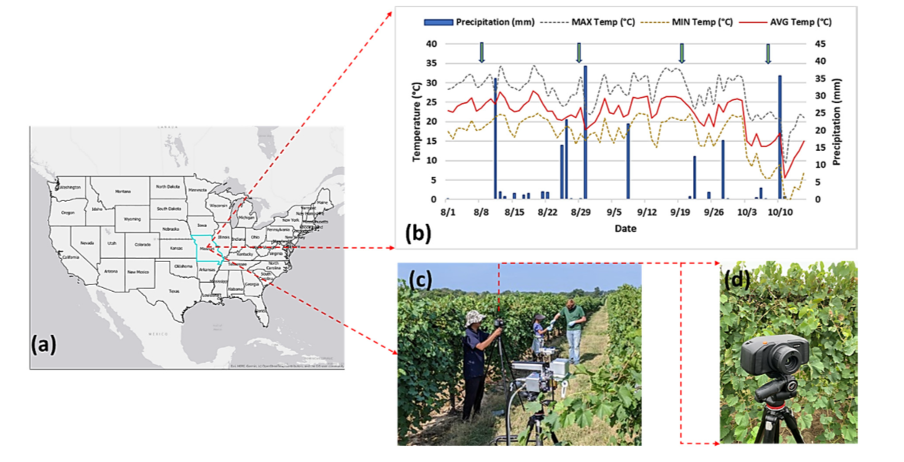
Рисунок 1.
а) Место проведения эксперимента — Научно-исследовательский центр Южной фермы Университета Миссури, г. Колумбия, штат Миссури (координаты: 38,92° северной широты, 92,28° западной долготы).
b) Средняя температура и количество осадков в период проведения эксперимента (лето 2019 года). Стрелки на графике (б) указывают даты проведения гиперспектральных измерений.
c) Датчик SPECIM IQ, установленный на штативе.
d) Увеличенное изображение датчика SPECIM IQ. Данный датчик позволяет получать гиперспектральные изображения с разрешением 512 × 512 пикселей и 204 спектральными диапазонами.
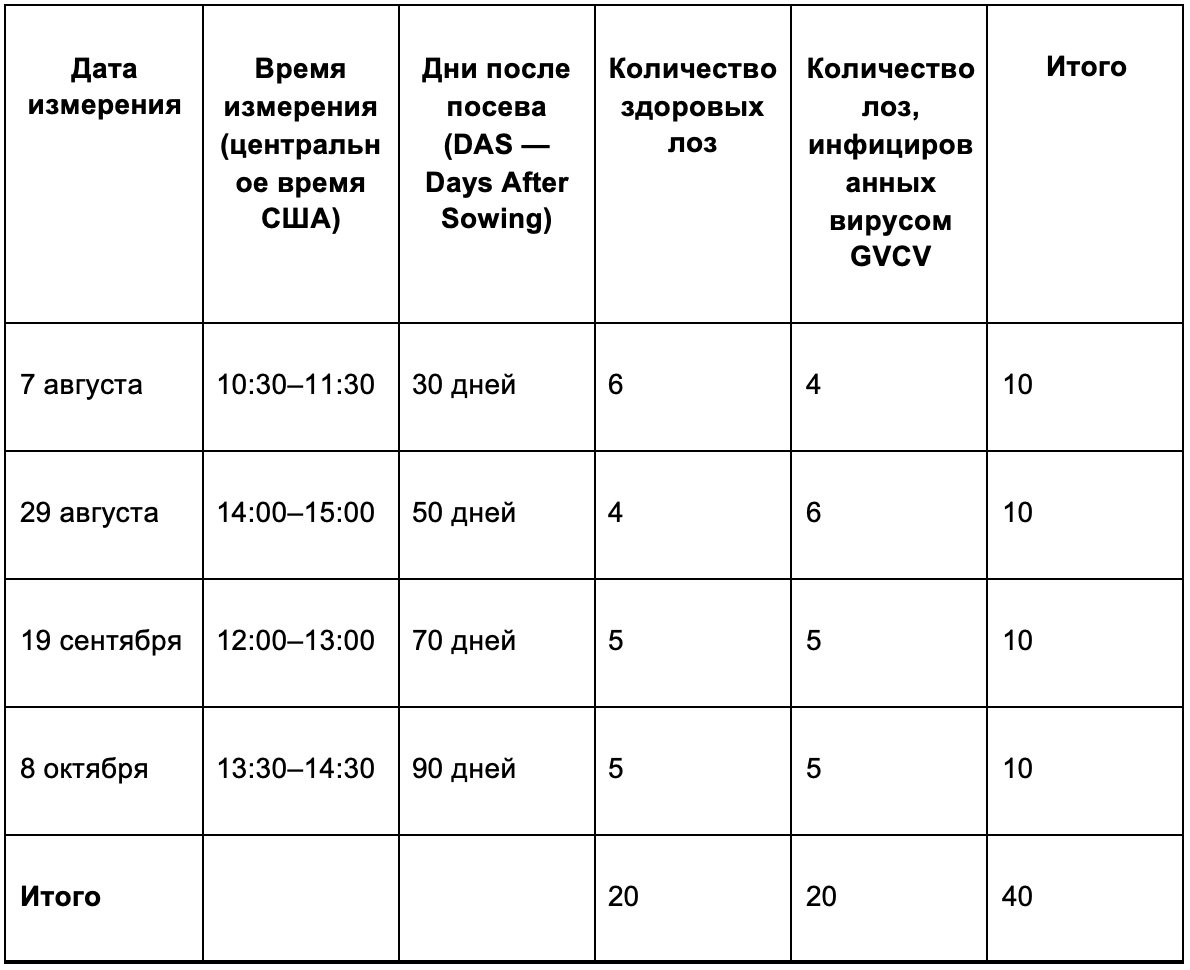
Гиперспектральные данные для здоровых и инфицированных лоз были собраны на различных стадиях инфицирования, соответствующих следующим датам: 7 августа, 29 августа, 19 сентября и 8 октября — это отражено в таблице 1.
Первый этап съёмки включал получение надирных изображений (съёмка строго сверху), когда все лозы были достаточно низкими, чтобы находиться в зоне досягаемости штатива с сенсором. На втором этапе были сделаны боковые снимки, поскольку лозы выросли и оказались выше штатива с сенсором.
Всего было получено 40 гиперспектральных изображений, из которых:
● 20 изображений — здоровые лозы;
● 20 изображений — инфицированные лозы.
Для сбора данных использовался гиперспектральный сенсор SPECIM IQ (компания Specim, г. Оулу, Финляндия) — портативная ручная система (см. рисунки 1c, d). Эта камера обеспечивает полный цикл измерений, включая: гиперспектральную съёмку; обработку данных; визуализацию результатов.
Принцип работы сенсора SPECIM IQ основан на технологии «push-broom»:
- Входящий световой поток проходит через призму (выпуклую решётку).
- Свет разделяется на узкие спектральные диапазоны.
- Данные фиксируются на светочувствительном чипе.
- Сенсор одновременно захватывает одну пространственную линию изображения со всем спектром, затем переходит к следующей линии (принцип «движения щётки»).
Технические характеристики сенсора:
● статический размер изображения: 512 × 512 пикселей;
● количество спектральных диапазонов (бандов): 204;
● диапазон длин волн: от 397 до 1004 нм;
● спектральное разрешение: 3 нм;
● видимая область: 0,55 × 0,55 м;
● пространственное разрешение: 1,07 мм (на расстоянии 1 м от объекта).
В рамках исследования съёмка лоз проводилась на уровне кроны на расстоянии 1–2 м. Более подробные технические характеристики сенсора SPECIM IQ можно найти в источнике [17].
Согласно рекомендациям для любых гиперспектральных систем, рядом с лозами для каждого гиперспектрального снимка размещалась белая панель ( [50]). Это позволяло: одновременно фиксировать спектральные характеристики лоз; документировать характеристики источников освещения.
Преобразование цифровых значений (DN) в отражательную способность выполняется автоматически с помощью встроенных функций.
SPECIM IQ поддерживает три режима обработки данных:
- Режим записи по умолчанию — без обработки, только сохранение данных.
- Режим автоматического скрининга (одноклассовый классификатор).
- Прикладной режим (многоклассовый классификатор) — позволяет выполнять классификацию прямо на сенсорном экране с подключением к ПО SPECIM IQ Studio.
Для дальнейшего анализа был выбран режим записи по умолчанию, чтобы сохранить: гиперспектральные «кубы» данных; поле зрения RGB (цветное изображение).
Таблица 1. Сводная информация о количестве образцов в зависимости от состояния здоровья лозы и дат измерений. GVCV вирус
2.2. Методы
2.2.1. Предварительная обработка гиперспектральных данных
Общий рабочий процесс нашего исследования графически представлен на рисунке 2.
Данные, полученные с камеры SPECIM IQ, представляли собой гиперспектральные изображения, скорректированные радиометрически. Затем эти данные были импортированы и предварительно проанализированы с помощью программного обеспечения ENVI (компания Harris Geospatial, Боулдер, Колорадо, США).
В ходе обработки из гиперспектральных «кубов» данных была удалена последняя спектральная полоса как шумовая — в результате осталось 203 спектральных полосы.
Для выделения лоз на фоне окружающего пространства использовался встроенный в ENVI классификатор метода опорных векторов (SVM) с ядром на основе радиальной базисной функции.
Далее был создан бинарный масочный слой — он позволил исключить пиксели фона и почвы, оставив только пиксели, соответствующие лозам (см. рисунок 3).
Общая точность классификации с помощью SVM составила от 84,4 % до 97,6 % — этот показатель рассчитан для 40 гиперспектральных изображений.
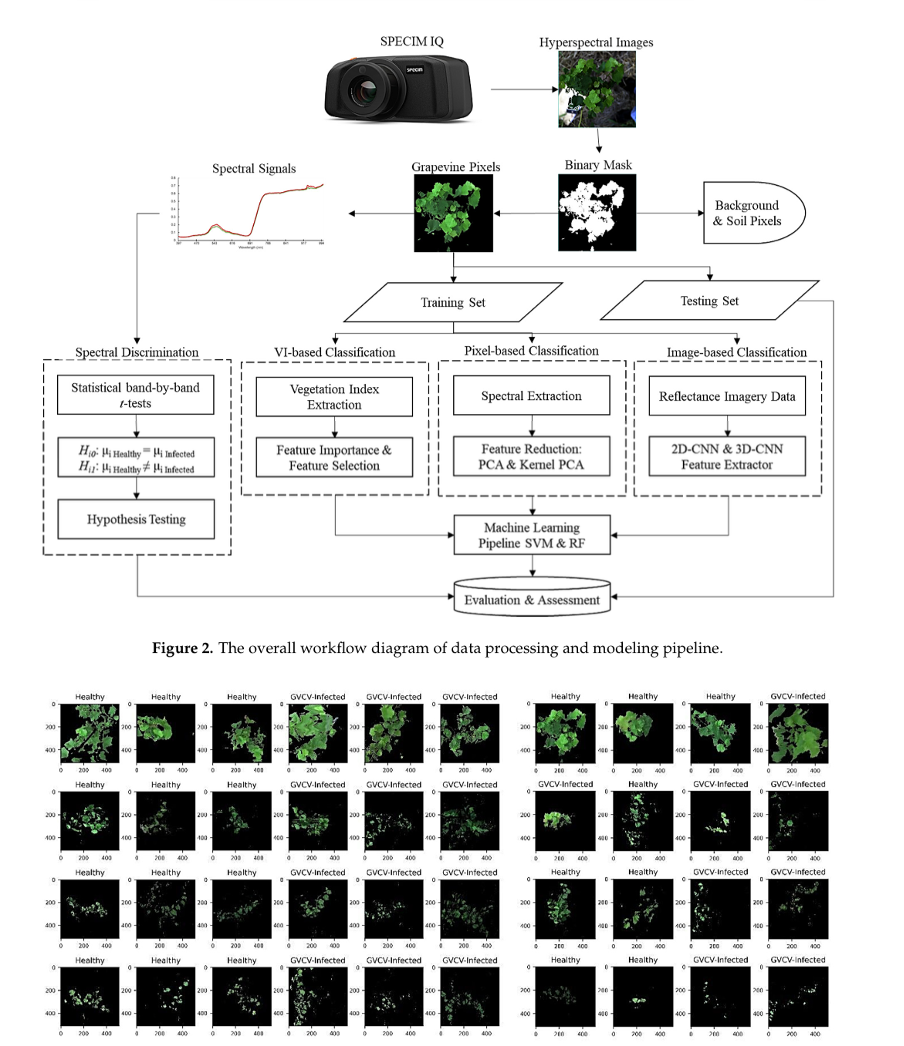
Рисунок 2-3. Псевдокрасно-зелено-синие (RGB) гиперспектральные изображения в обучающем наборе (n = 24 изображения) и тестовом наборе (n = 16 изображений). Размеры изображений: 512 × 512 пикселей × 203 спектральных полосы. Порядок строк соответствует датам измерения (7 августа, 29 августа, 19 сентября и 8 октября). Обучающие изображения (3 здоровых и 3 виноградных лозы с GVCV) были случайным образом выбраны из каждого измерения. Фоновые изображения (почва, трава, небо и т. д.) были замаскированы, и после сегментации были сохранены только пиксели виноградных лоз. Изображения от 7 августа (первый ряд) были получены под вертикальным (надиральным) углом. Последующие изображения были получены под горизонтальным (латеральным) углом.
Для обучающего и тестового наборов мы случайным образом отобрали по 3 гиперспектральных изображения из 2 классов (здоровые лозы и лозы, инфицированные вирусом GVCV) для каждой даты измерения (всего 4 даты). В результате было сформировано:
● 24 изображения для обучающего набора;
● 16 изображений для тестового набора.
Для классификации, основанной на вегетационных индексах (VI) и попиксельной классификации, были выполнены следующие шаги:
- Извлечены «чистые» пиксели, соответствующие лозам (см. рисунок 4).
- Проведена передискретизация (ресэмплинг) пикселей для устранения дисбаланса классов (когда один класс значительно преобладает над другим).
Далее данные со всех дат были объединены в единый набор данных, который получил название «combined data»(«объединённые данные») (см. рисунок 4e, j). Цель объединения — снизить влияние геометрических искажений при съёмке.
Из-за ограничений по вычислительным ресурсам модель обучалась только на 10 000 случайных пикселей из обоих классов, взятых из 24 изображений обучающего набора (спектральные сигналы представлены на рисунке 4a–e).
Затем обученная модель была протестирована на всех пикселях из 16 изображений тестового набора (спектральные сигналы показаны на рисунке 4f–j).
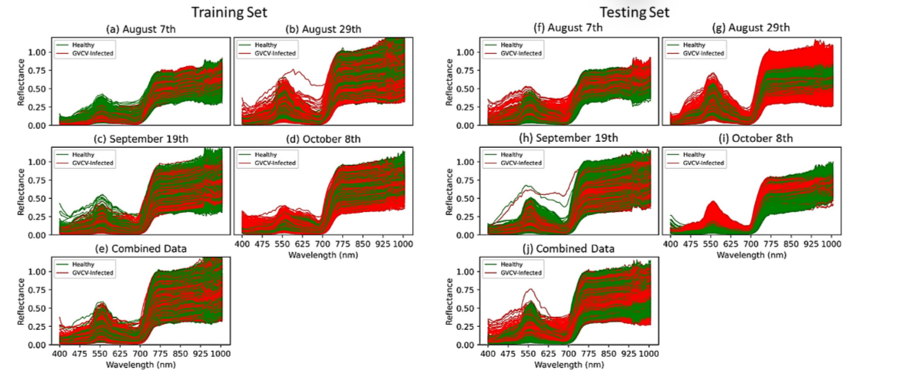
Рисунок 4. Спектральный профиль 10 000 случайных пикселей, одинаково помеченных как здоровые или инфицированные GVCV, в обучающем наборе (a–e)
e) и тестовом наборе (f–j). Спектральные данные были передискретизированы для обеспечения баланса между двумя классами.
2.2.2. Дискриминация спектральных сигналов отражения
Для изучения различий между спектрами отражения здоровых лоз и лоз, инфицированных GVCV, для каждого набора данных, соответствующего каждой дате сбора, применялись независимые t-тесты по каждой полосе спектра. Цель — исследовать спектральные изменения, которые можно однозначно связать с определённой стадией инфекции, а также проанализировать объединённый набор данных.
Были учтены три статистических предположения, необходимых для проведения t-теста:
- Независимость двух групп — предполагалось, что две группы (здоровые и инфицированные лозы) независимы друг от друга.
- Нормальное распределение зависимой переменной — предполагалось, что значения отражения для каждой полосы спектра распределены нормально. Это было подтверждено анализом асимметрии (скошенности) и эксцесса (островершинности) распределения.
- Равенство дисперсий для зависимой переменной (гомогенность дисперсии) — предполагалось, что дисперсии значений отражения в двух группах примерно равны. Тесты Левена [51] не выявили значимых различий для всех полос спектра, что позволило использовать t-тесты с объединённой (равной) дисперсией, как показано в уравнении (1).
Уравнение (1):
SDp2=(n1−1)+(n2−1)(n1−1)SD12+(n2−1)SD22
где:
● SDp2 — объединённая дисперсия;
● n1 и n2 — размеры выборок для первой и второй групп соответственно;
● SD12 и SD22 — дисперсии для первой и второй групп.
Результат, полученный из уравнения (1), был подставлен в уравнение (2) для расчёта t-значений.
Уравнение (2):
t=SE(M1−M2)M1−M2
где:
● M1 и M2 — средние значения для первой и второй групп;
● SE(M1−M2) — стандартная ошибка разности средних, рассчитываемая по формуле:
SE(M1−M2)=n1SDp2+n2SDp2
Таким образом, расчёты позволили оценить статистически значимые различия в спектрах отражения между здоровыми и инфицированными лозами.
где M1 — среднее значение отражательной способности полосы i здоровых лоз; M2 — среднее значение отражательной способности полосы i зараженных лоз; n1 — количество образцов здоровых лоз; n2 — количество образцов зараженных лоз; SD2
p — объединенная дисперсия. Поскольку мы сравнивали разницу в средних значениях спектральной отражательной способности каждой полосы между здоровыми и зараженными виноградными лозами, ненаправленные гипотезы обозначались следующим образом:
Нулевая гипотеза Hi0: µi Здоровая лоза = µi GVCV лоза
Альтернативная гипотеза Hi1: µi Здоровая лоза ̸ = µi GVCV лоза
2.2.3. Классификация растительности по индексам
На основе пикселей изображений виноградных лоз, полученных с помощью гиперспектральной съёмки, были рассчитаны спектральные индексы. Индексы отражают состояние свойств растений — данные взяты из ранее проведённых исследований (обзор литературы).
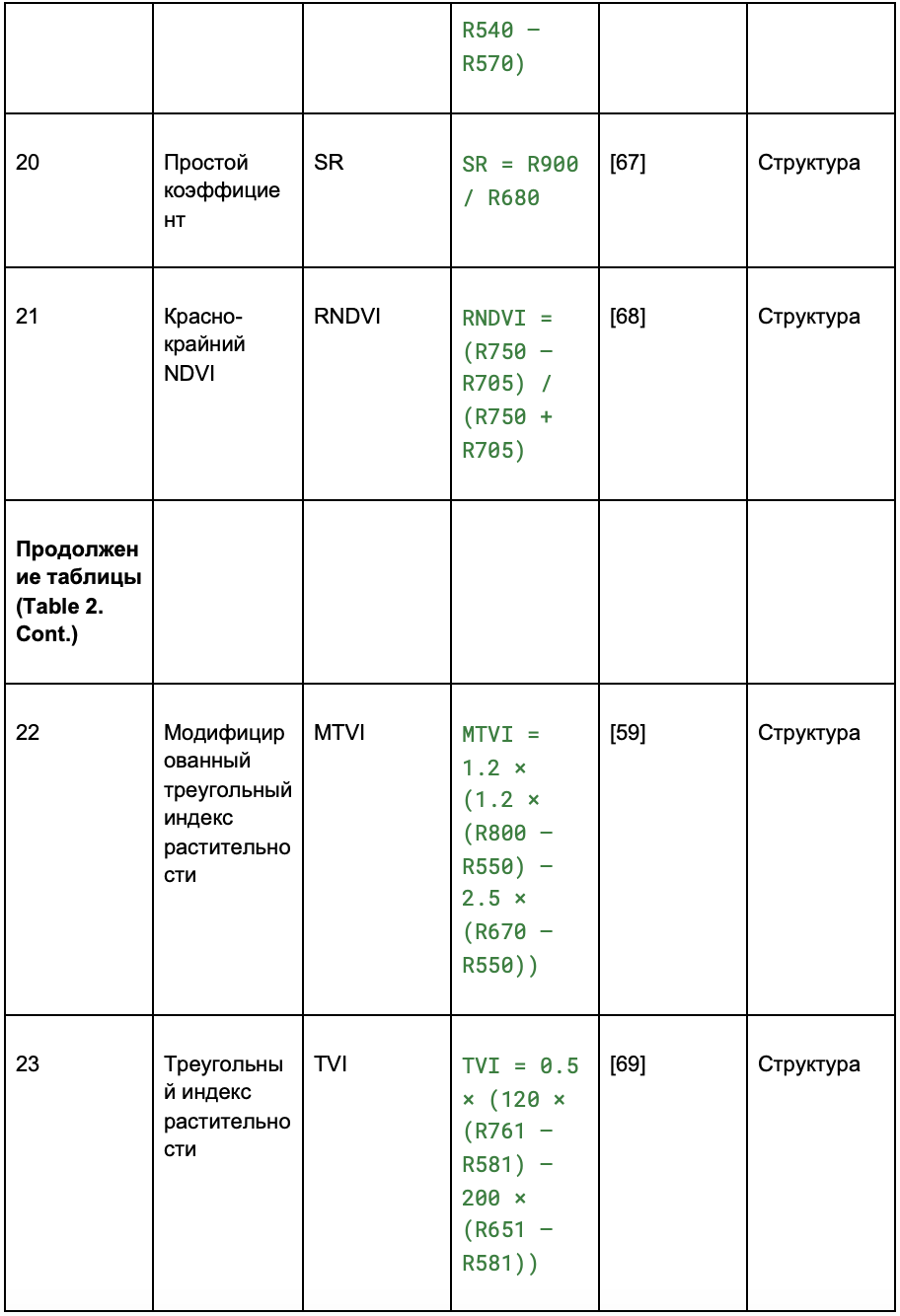
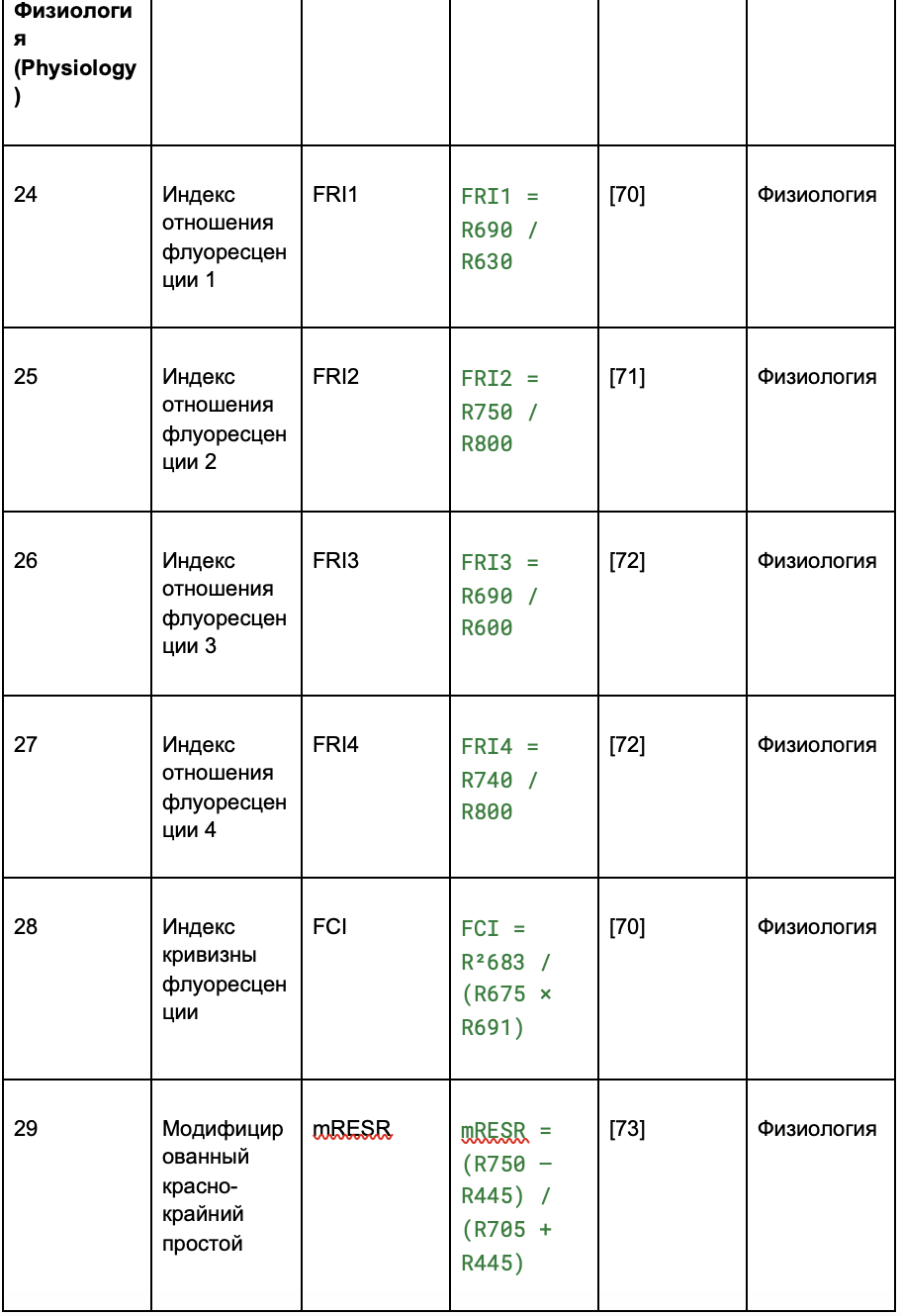
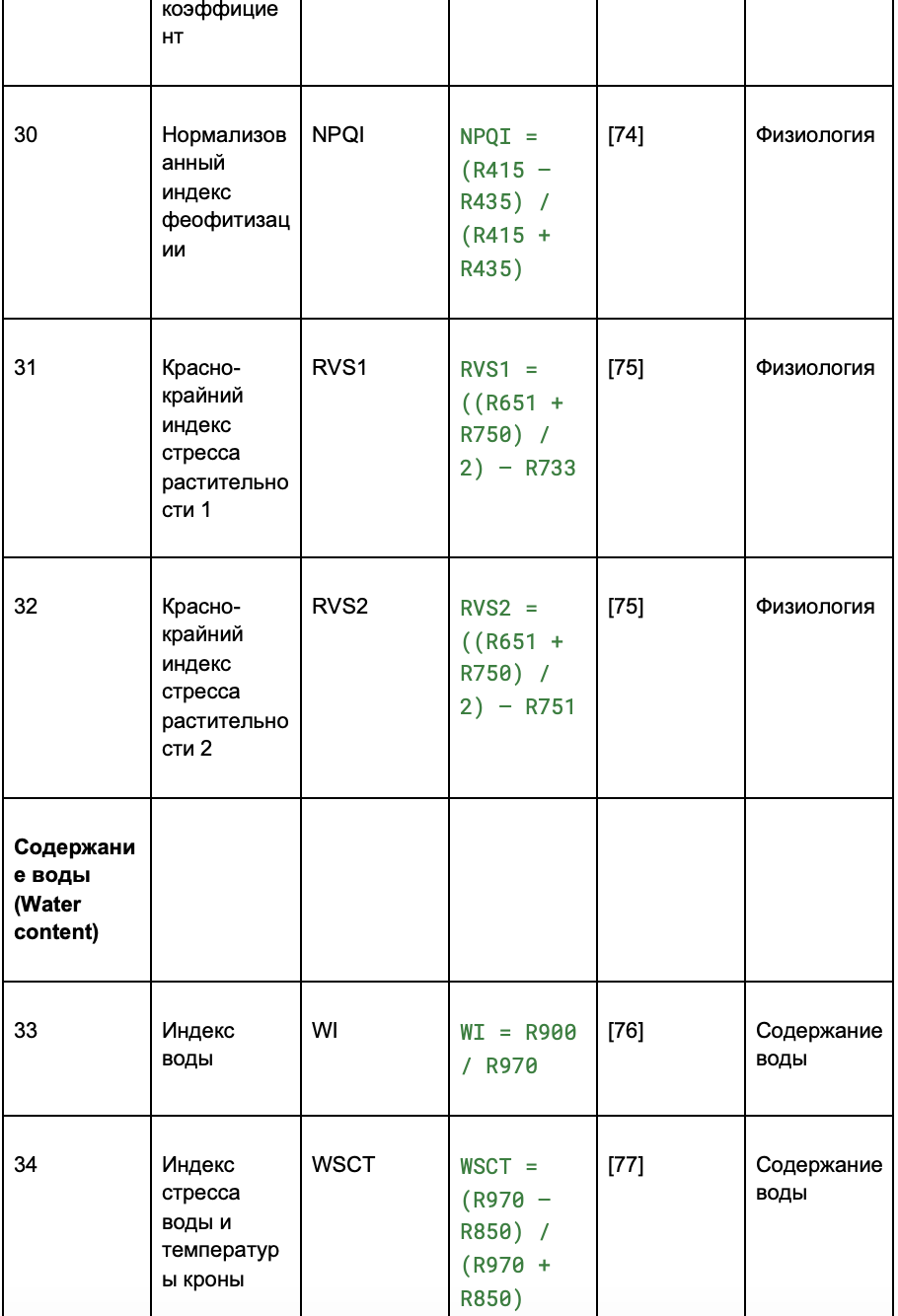
В таблице 2 индексы разделены на четыре категории:
- пигменты;
- структура;
- физиология;
- содержание воды.
Перед моделированием данных был проведён этап инженерного проектирования признаков (feature engineering), который включал:
● бинарное кодирование (0 — здоровые лозы; 1 — заражённые лозы);
● масштабирование данных;
● отбор признаков (feature selection).
В процессе отбора признаков были отфильтрованы и удалены несущественные или частично релевантные вегетационные индексы (ВИ). Цель этого шага: уменьшить объём избыточных данных; снизить сложность алгоритма; повысить точность модели; ускорить процесс обучения модели.
Значимость ВИ для итогового результата оценивалась с помощью метода важности признаков случайного леса (random forest feature importance), который также известен как средняя уменьшенная примесь (MDI)[45].
Среднее значение оценки стало пороговым значением для сохранения значимых ВИ.
Метод MDI был выбран из-за его устойчивости к мультиколлинеарности (высокой корреляции между признаками) [35].
Таблица 2. Извлечение вегетационных индексов (VIs) из гиперспектральных изображений
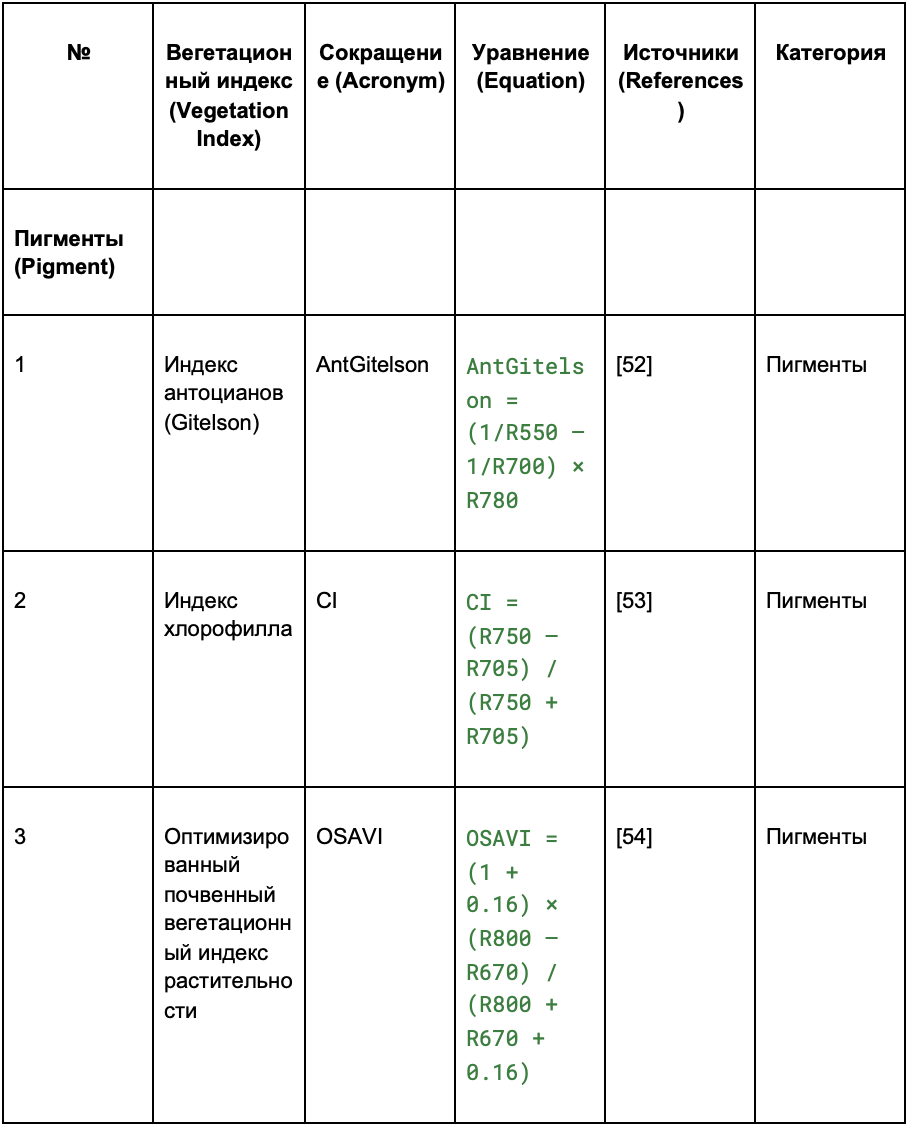
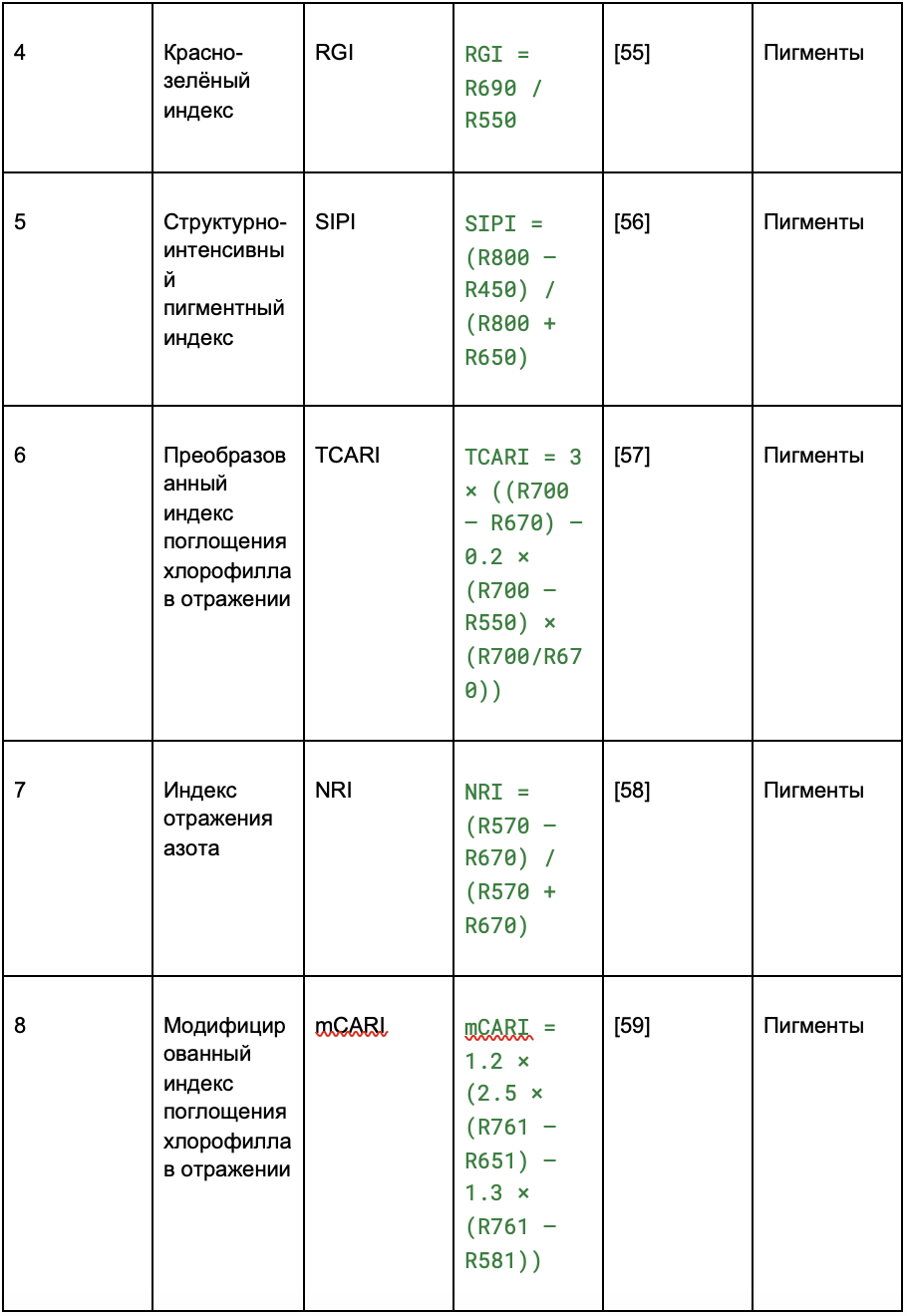
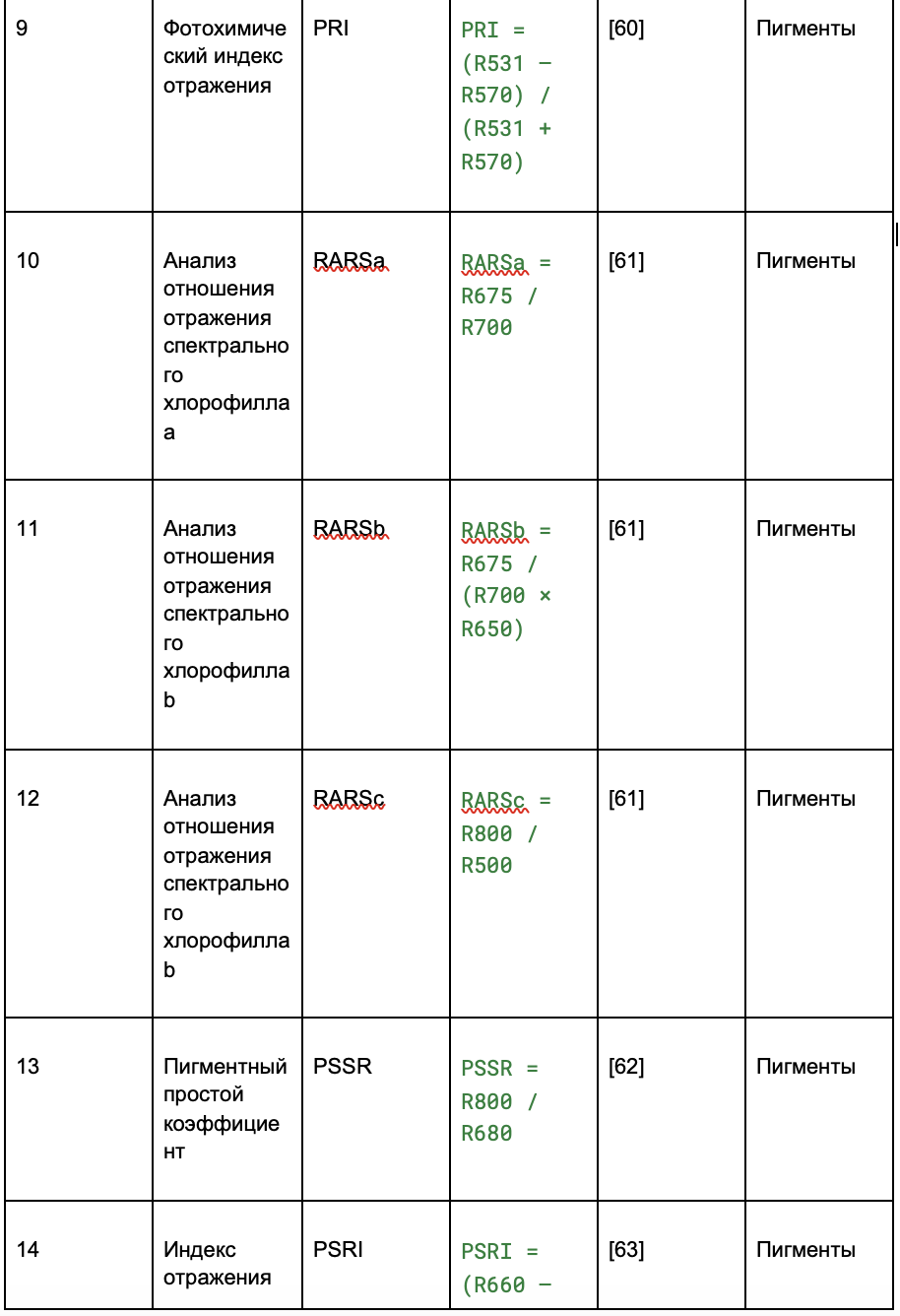
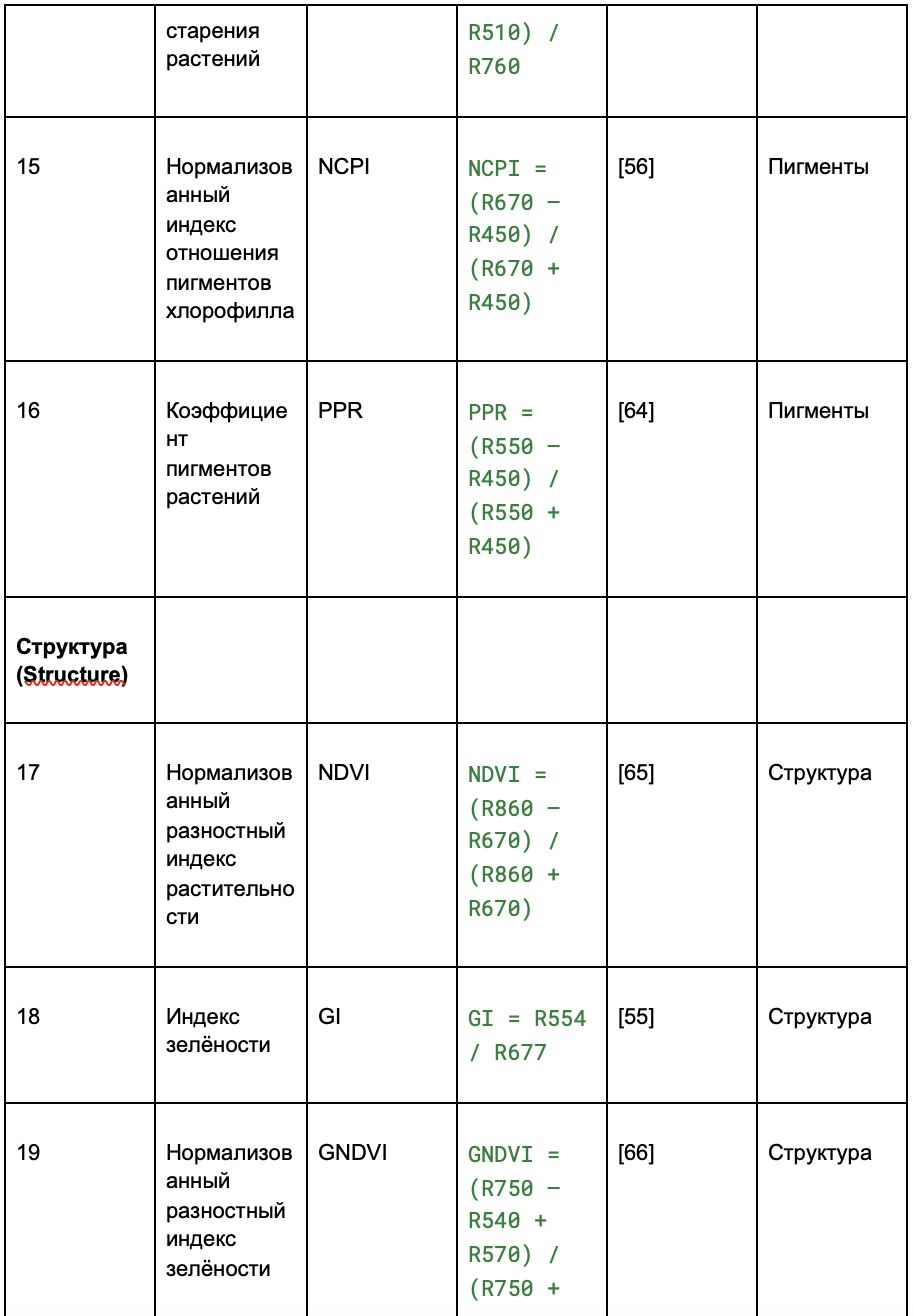
2.2.4. Попиксельное выделение признаков и их сокращение
Каждый пиксель содержал 203 спектральных диапазона. Мы использовали два различных метода выделения признаков, чтобы сжать данные и уменьшить количество признаков, сохранив при этом большую часть значимой информации. В качестве неконтролируемых преобразований данных применялись метод главных компонент (PCA) и метод главных компонент с использованием ядра (Kernel‑PCA).
Метод PCA позволяет проецировать многомерные данные в новое подпространство с меньшим числом измерений. На выходе PCA получаются главные компоненты — ортогональные оси нового подпространства, которые отражают направления максимальной дисперсии.
В то время как PCA работает исходя из предположения о линейной разделимости данных, Kernel‑PCA (расширение метода PCA) способен решать нелинейные задачи благодаря использованию функции с ядром.
Для настройки гиперпараметров и выбора наилучшей модели были использованы три распространённых ядра: полиномиальное; гиперболический тангенс (сигмоида); радиальная базисная функция (RBF).
2.2.5. Конвейер машинного обучения (Machine Learning Pipeline)
Был создан последовательный конвейер классификации для предварительной обработки и классификации двух классов. Процесс начался с нормализации данных в диапазоне от 0 до 1, а также с разработки признаков (feature engineering):
● отбор признаков для модели, основанной на вегетационных индексах (VI-based model);
● извлечение признаков для пиксельной модели (pixel-based model).
Также были задействованы два конкурирующих классификатора: SVM (Support Vector Machine) и RF (Random Forest).
Для повышения эффективности работы с высокосложными и нелинейными данными классификатор SVMнастраивался с помощью:
● ядер (kernels) — «трюки» с ядрами позволяют преобразовать исходные данные в пространство признаков более высокой размерности, где данные становятся разделимыми;
● функции штрафа (cost penalization function), определяемой параметрами C — этот параметр контролирует штраф за ошибочную классификацию и ширину полей (margins), позволяя настраивать баланс между смещением (bias) и дисперсией (variance):
○ большие значения C соответствуют большим штрафам за ошибки и повышенной чувствительности к ошибкам классификации;
○ меньшие значения C работают наоборот;
● значений гамма (gamma values) — определяют, насколько быстро рассеиваются границы классов по мере удаления от опорных векторов (support vectors).
В случае классификатора Random Forest (RF) были рассмотрены следующие гиперпараметры:
● количество деревьев в лесу (number of trees in the forest);
● максимальное количество признаков, учитываемых при разбиении узла (maximum number of features considered to split a node);
● максимальное количество уровней в каждом дереве решений (maximum number of levels in each decision tree);
● минимальное количество точек данных, размещаемых в узле перед его разбиением (minimum number of data points placed in a node before the node is split);
● минимальное количество точек данных, разрешённых в конечном узле (leaf node) (minimum number of data points allowed in a leaf node);
● использование замены при выборке точек данных (bootstrap) — определялось, применяется ли замена при выборке.
Для настройки этих гиперпараметров на каждом этапе всего конвейера была добавлена техника поиска по сетке (grid search).
Метрикой для оценки производительности модели являлась точность (accuracy score), рассчитанная как отношение количества правильно классифицированных пикселей и изображений (истинных положительных результатов и ложных отрицательных результатов) ко всем классифицированным пикселям и изображениям.
Для оценки моделей сравнивали значения точности на отложенном тестовом наборе данных (hold-out test set).
Особо стоит отметить, что для классификации изображений: был отдельно и независимо от процессов обучения и валидации выделен тестовый набор из 16 гиперспектральных изображений (см. рисунок 3); эти изображения не использовались в обучении и проверке модели.
Для классификации по вегетационным индексам и попиксельной классификации использовали чистые пикселииз этих же 16 гиперспектральных изображений (тестовый набор представлен на рисунках 4f–j).
В процессе обучения модели применялась 5-кратная кросс-валидация (5-fold cross validation), чтобы снизить вероятность: недообучения модели (underfitting); переобучения модели (overfitting).
Конвейер машинного обучения был разработан и реализован с использованием: языка программирования Python 3.8; библиотеки Scikit-learn.
2.2.6. Экстракторы признаков сверточных нейронных сетей (CNN) и классификация изображений
В контексте данных изображений обычно имеет смысл предполагать существование пространственных паттернов, в которых соседние пиксели более важны, чем удаленные пиксели. Сверточный слой, как правило, очень хорошо справляется с задачами, связанными с изображениями, благодаря своей способности эффективно извлекать пространственно-спектральные представления изображений. Архитектура обычно состоит из нескольких или сотен сверточных и пулинговых (субдискретизирующих) слоев, за которыми следуют несколько полносвязных слоев в конце. Ранние сверточные слои служат в качестве экстракторов признаков, которые могут извлекать низкоуровневые признаки, такие как края и пятна, из исходных изображений.
Эти низкоуровневые признаки объединяются послойно для формирования высокоуровневых признаков в виде сложных форм, таких как контуры. Сверточные слои обычно работают в тандеме со слоями пулинга, чтобы уменьшить сложность сети, ускорить вычисления,и избежать переобучения. Например, слой пулинга с операцией max (максимальный пулинг) уменьшает высоту и ширину карт активации, созданных предыдущим сверточным слоем, но сохраняет глубину карт активации. Слои пакетной нормализации часто размещаются между сверточными блоками и блоками пулинга. Они добавляются для смягчения проблем нестабильности градиента в глубокой сети и для уменьшения переобучения, соответственно. После серии сверточных слоев и слоев пулинга трехмерная карта активации проходит через слой выравнивания и сворачивается в массив одномерных векторов. Помимо функциональности 2D-CNN, трехмерный сверточный слой (3D-CNN) может одновременно извлекать признаки как из пространственного, так и из спектрального измерений, тем самым эффективно захватывая пространственно-спектральные паттерны, закодированные в нескольких смежных пикселях и длинах волн.
Из-за крайне небольшого объёма выборки — всего 40 гиперспектральных изображений — мы адаптировали архитектуру сети (см. рисунок 5). Для этого использовали блоки 2D-CNN и 3D-CNN в качестве автоматических экстракторов признаков (извлекателей характеристик изображения). Затем обучили модель на сокращённом наборе признаков с помощью конвейера машинного обучения, описанного выше.
Архитектура глубокой нейронной сети для извлечения признаков была разработана с опорой на AlexNet [78] — благодаря её простоте и пригодности для задач бинарной классификации.
Мы тщательно изучили и подобрали гиперпараметры для моделей 2D-CNN и 3D-CNN с целью их последующего сравнения. Среди настроенных гиперпараметров:
● количество фильтров (filters);
● размеры ядер свёртки (kernel sizes);
● размеры пулов (pool sizes).
Конкретные параметры архитектуры выглядели следующим образом:
- Количество фильтров в свёрточных слоях:
○ 8 фильтров — в первых блоках;
○ 16 и 32 фильтра — в последующих блоках;
○ 64 фильтра — в последнем слое.
- Размер ядра свёртки:
○ для модели 2D-CNN — 3 × 3 пикселя;
○ для модели 3D-CNN — 3 × 3 × 3 пикселя (с шагом (stride) равным 1).
- Размер пулов для слоёв max pooling — идентичен размеру ядра свёртки.
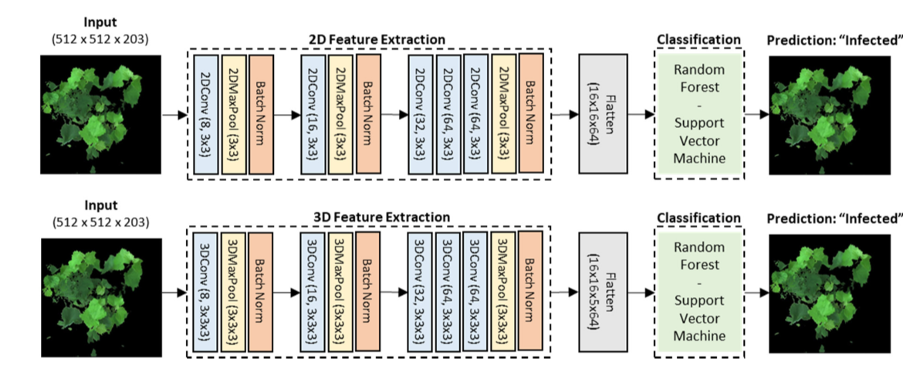
Рисунок 5. Схема архитектуры для классификации изображений
Исходные размеры гиперспектральных изображений составляли 512 × 512 пикселей × 203 спектральных диапазона.
Для автоматического извлечения признаков использовалась сеть, построенная на основе архитектуры AlexNet [78]. При этом гиперпараметры — количество фильтров, размеры ядер свёртки и размеры пулов — подбирались экспериментально. Для обеспечения сопоставимости результатов значения этих параметров были одинаковыми как для 2D‑CNN, так и для 3D‑CNN.
Результаты сокращения данных: 2D‑CNN преобразовала кубические данные в представление размером 16 пространственных признаков × 16 пространственных признаков × 64 свёрточных фильтра; 3D‑CNNпреобразовала кубические данные в представление размером 16 пространственных признаков × 16 пространственных признаков × 5 спектральных признаков × 64 свёрточных фильтра.
Далее сокращённые признаки были сглажены (преобразованы в одномерный массив) и переданы в конвейеры машинного обучения для классификации: RF (Random Forest); SVM (Support Vector Machine).
3. Результаты
3.1. Статистический анализ для различения спектральных сигнатур
Разделимость спектров между здоровыми лозами и лозами, заражёнными GVCV, на ранних стадиях заражения показана на рисунке 6.
Ранняя стадия (7 августа, рисунок 6a). В видимом диапазоне волн (VIS) различий не обнаружено, но они выявлены в области ближней инфракрасной области спектра (NIR, 800–1000 нм). Спектры отражения для лоз, заражённых GVCV, были выше, чем для здоровых, на более длинных волнах. t‑тест подтвердил статистическую значимость различий в диапазоне 900–940 нм (p<0,05).
Следующие даты измерений (29 августа и 19 сентября, рисунки 6b и 6c соответственно). В NIR‑области спектральный показатель для лоз с GVCV немного снизился по сравнению со здоровыми образцами. Однако это изменение было небольшим и незначимым: статистический анализ показал высокие значения p (p>0,3) для обоих измерений.
Поздняя стадия (8 октября, рисунок 6d). Наиболее отчётливые и различимые различия между спектральными значениями здоровых и заражённых лоз выявлены в видимом диапазоне и красной краевой области (VIS и red‑edge, 400–700 нм). Значения для здоровых лоз были ниже, чем для заражённых, что подтверждено значимым t‑тестом в диапазоне длин волн 449–461 нм.
В отношении NIR‑длин волн (720–920 нм) на этой поздней бессимптомной стадии картина была идентична той, что наблюдалась 7 августа: сигнал от заражённых растений был выше, хотя статистически это не подтверждалось.
Объединение наборов данных на бессимптомных стадиях (рисунок 6e). При объединении данных на разных бессимптомных стадиях расхождение спектрального показателя для здоровых лоз и лоз с GVCV уменьшилось и стало неразличимым — особенно в NIR‑диапазоне. Уровень достоверности также снизился до 80% (p<0,2) для статистического подтверждения различий в VIS‑спектрах здоровых лоз и лоз с GVCV.
Эффект в диапазоне 925–930 нм. Вне зависимости от набора данных наблюдалось резкое увеличение значений отражения в диапазоне 925–930 нм. Этот эффект был вызван атмосферным поглощением и поглощением водой в этих диапазонах при проведении измерений на открытом воздухе под прямыми солнечными лучами [17].
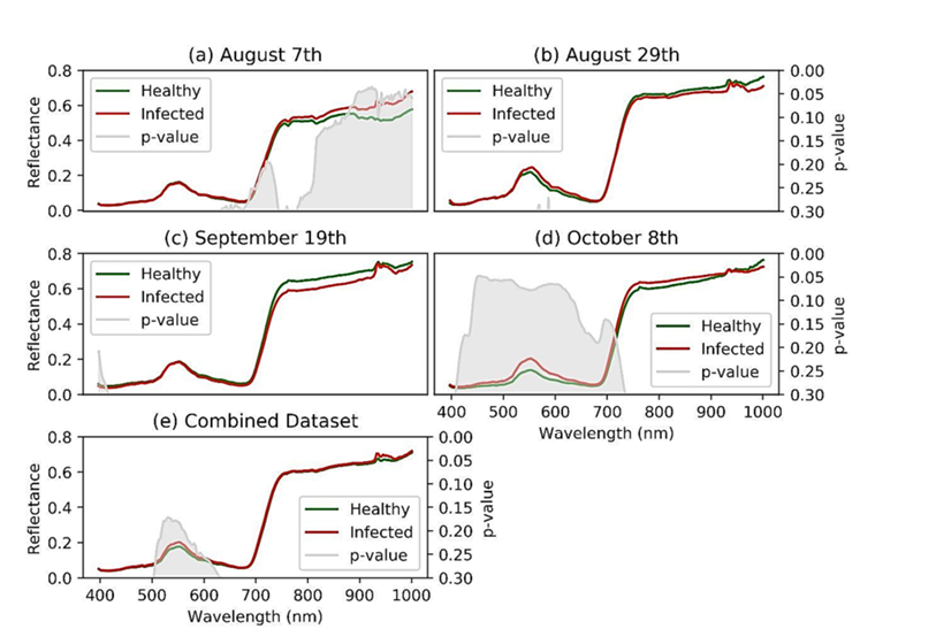
Рисунок 6. Дискриминация сигнатур спектров отражения для здоровых и зараженных GVCV виноградных лоз на ранних стадиях заражения. 20-дневные гиперспектральные измерения виноградных лоз через 30 дней после посева (DAS) проводились 7 августа (a), 29 августа (b), 19 сентября (c) и 8 октября (d) 2019 года. Данные за все даты были объединены и названы «объединенным набором данных» (e), поскольку все измерения проводились на бессимптомных стадиях. Для проверки уровня достоверности спектральной дискриминации был применен t-критерий для независимых выборок. Для расчета p-значений (в серых областях) был проверен уровень достоверности спектральной дискриминации.
3.2. Классификация растительности по индексам
С помощью функции уменьшения примеси в среднем на основе случайного леса (MDI — Mean Decreased Impurity) была определена важность признаков. Функция вернула нормализованные оценки для всех 34 вегетационных индексов (VIs) и ранжировала их по способности классифицировать здоровые лозы и лозы, заражённые GVCV.
Техника MDI, применённая 8 августа (рис. 7а), выделила два физиологических индекса (NPQI и FRI₁) и пигментный индекс (Ant_Gitelson) как наиболее значимые характеристики.
Для измерений, проведённых 29 августа (рис. 7b), наиболее важным индексом стал FRI₁ — его оценка значительно превышала значения других индексов. Эта значимость сохранялась в течение следующих 20 дней — до 19 сентября (рис. 7c). В дополнение к этому был отмечен ещё один пигментный индекс — PSRI.
К 19 сентября оба водных индекса (WSCT и WI) начали входить в пятёрку наиболее значимых показателей.
На дату последнего измерения (рис. 7d) водные индексы стали двумя наиболее важными характеристиками для классификации здоровых и заражённых лоз, в то время как значимость FRI₁ снизилась.
Техника отбора признаков для объединённого набора данных (рис. 7e) показала, что ключевыми индексами для классификации являются FRI₁, WSCT и Ant_Gitelson.
Следует отметить, что сумма всех нормализованных значений равна 1,0. Если два или более индекса VIs сильно коррелируют, один из них может иметь высокие значения, в то время как информация о других индексах может быть не полностью учтена.
В качестве порога для отбора признаков, которые будут включены в конвейер машинного обучения (рис. 7f) для задачи классификации, было установлено среднее значение оценок.
Классификация с помощью метода опорных векторов (SVM) оказалась чуть точнее, чем с помощью классификатора случайного леса (RF). Именно классификатор RF был выбран для тестирования.
В процессе обучения точность 5-кратной кросс-валидации составила: для классификатора SVM — до 96,75% (данные от 29 августа); для классификатора RF — минимум 82,13% (данные от 8 октября).
Точность для тестового набора данных достигла 67,81% для данных от 7 августа и заметно варьировалась для последующих измерений.
Объединённые данные продемонстрировали лучшую стабильность между оценками обучения: 85,86% для классификатора RF; 90,24% для SVM; 65,70% для оценки тестирования.
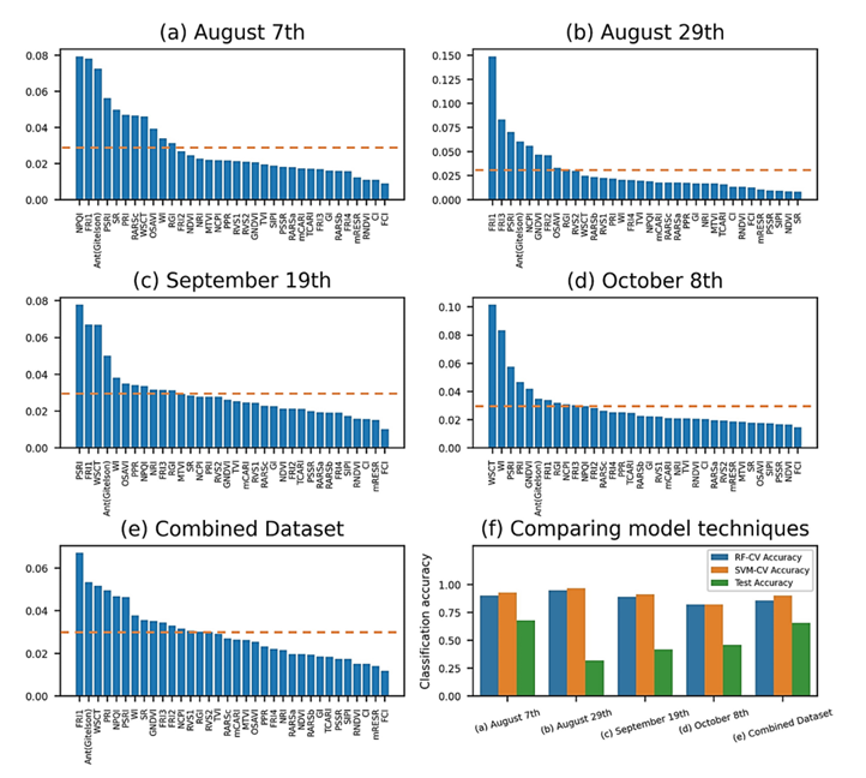
Рисунок 7. Средняя важность признаков уменьшенной примеси (MDI) среди наборов данных (a–e). Нормализованные оценки для 34 индексов растительности были ранжированы по их соответствующей способности к классификации. Пунктирные линии показывают среднее значение оценок, которое являлось пороговым значением, используемым для включения выбранных индексов растительности в конвейер машинного обучения. Производительность классификации на основе индексов растительности (f). В процессе обучения точность 5-кратной перекрестной проверки из конвейеров SVM (оранжевые столбцы) была неизменно выше, чем точность из конвейеров RF (синие столбцы), поэтому для тестирования были выбраны конвейеры SVM (зеленые столбцы).
3.3. Классификация по пикселям (Pixel-Wise Classification)
Из 203 спектральных диапазонов (полос) каждого пикселя на гиперспектральных изображениях были извлечены характеристики. Эти характеристики были преобразованы (проецированы) в новые пространства признаков с размерностью 2, 50, 100 и 150 признаков с помощью методов PCA (анализ главных компонент) и Kernel-PCA. Затем полученные данные были переданы в конвейер машинного обучения с использованием классификаторов SVM (метод опорных векторов) и RF (случайный лес) (см. рисунок 8a–e).
Независимо от набора данных и выбранного классификатора, наилучшие результаты показали методы PCA с использованием больших пространств признаков (50, 100 и 150 признаков). Точность валидации превысила 95% по сравнению с моделями Kernel-PCA и моделями с 2 признаками.
Классификатор RF практически во всех случаях превосходил SVM как по наборам данных, так и по методам уменьшения размерности признаков.
Конвейеры машинного обучения продемонстрировали следующие максимальные значения точности при кросс-валидации: 94,70% (модель с 50 признаками) — для данных от 7 августа; 95,30% (модель с 50 признаками) — для данных от 29 августа; 91,60% (модель с 50 признаками) — для данных от 19 сентября; 89,70% (модель с 100 признаками) — для данных от 8 октября; 85,10% (модель с 100 признаками) — для объединённого набора данных.
Далее обученные конвейеры были протестированы на независимом тестовом наборе данных (см. рисунок 8f). Точность классификации на тестовом наборе составила: 77,75% — для данных от 7 августа; 41,89% — для данных от 29 августа; 28,71% — для данных от 19 сентября; 58,80% — для данных от 8 октября; 73,62% — для объединённого набора данных.
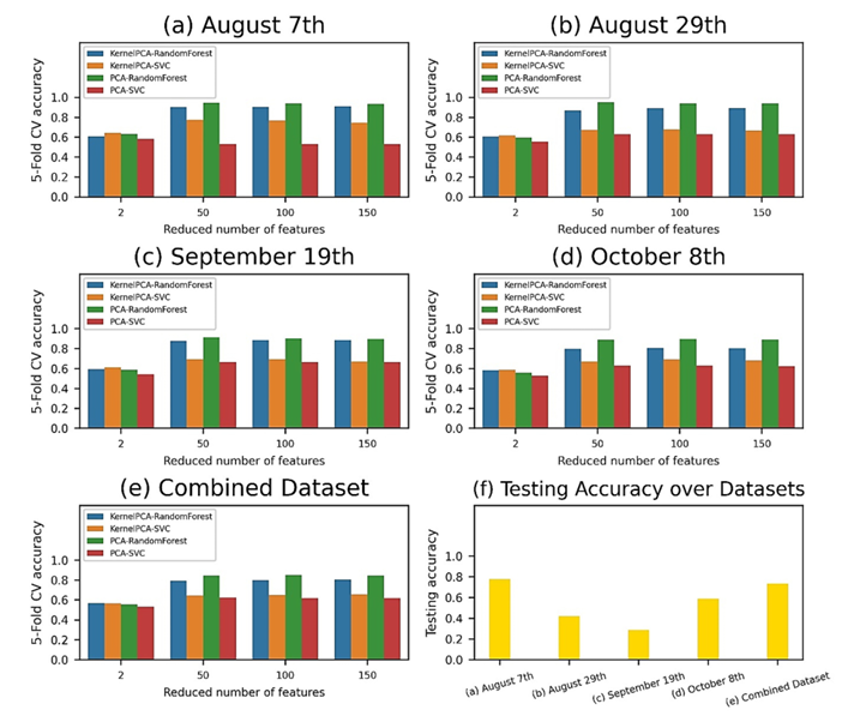
Рисунок 8. Точность классификации по пикселям (pixel-wise) для различных конвейеров машинного обучения и наборов данных.
На графике показана точность 5-кратной кросс-валидации (CV — cross validation) при уменьшении числа признаков для следующих наборов данных: 7 августа (а); 29 августа (b); 19 сентября ©; 8 октября (d); объединённый набор данных (e).
Наилучшие результаты показали конвейеры, использующие метод главных компонент (PCA) в сочетании с алгоритмом «случайный лес» (random forest) со следующим количеством признаков: для данных от 7 августа — модель с 50 признаками (точность 94,70%); для данных от 29 августа — модель с 50 признаками (точность 95,30%); для данных от 19 сентября — модель с 100 признаками (точность 91,60%); для данных от 8 октября— модель с 100 признаками (точность 89,70%); для объединённого набора данных — модель с 100 признаками (точность 85,10%).
Эти конвейеры были выбраны для дальнейшей оценки на тестовом наборе данных (f).
3.4. Автоматизированное извлечение признаков с помощью 2D-CNN и 3D-CNN и классификация изображений
Двумерная свёрточная нейронная сеть (2D-CNN) выполняла функцию автоматического извлечения признаков, позволяя уменьшить размерность гиперспектральных изображений с высокого уровня детализации (512 × 512 пикселей × 203 спектральных каналов — ширина × высота × спектральные каналы, см. рисунок 3) до значительно меньшего размерного пространства данных: 16 × 16 пикселей × 64 фильтров (ширина × высота × свёрточные фильтры), как показано на рисунке 9а.
Аналогичным образом экстракторы признаков на основе 3D-CNN преобразовали исходные изображения до нового размерного эквивалента, соответствующего выходу 2D-CNN — 16 × 16 пикселей × 5 спектральных каналов × 64 фильтров (ширина × высота × спектральные каналы × свёрточные фильтры), как показано на рисунке 9b.
Ключевое различие между экстракторами признаков 2D-CNN и 3D-CNN заключается в способе преобразования спектральных признаков. Для 2D-CNN: первый свёрточный слой мгновенно преобразовывал все 203 спектральных признака, а также некоторые пространственные признаки. Для 3D-CNN: фильтры поэтапно усваивали пространственно-спектральные признаки на каждом слое, обрабатывая их и постепенно сокращая до 5 спектральных признаков на последнем слое.
Кроме того:
· Блоки 2D-CNN с ядром размером 3 × 3 пикселя преобразовывали признаки отдельно для каждого спектрального канала.
· Блоки 3D-CNN использовали куб ядер размером 3 × 3 × 3 для одновременного преобразования пространственно-спектральных признаков.
Параллельное преобразование в 3D-CNN позволило лучше извлекать признаки из гиперспектральных «кубов» данных. Однако у этого подхода есть недостатки: большее количество обучаемых параметров в каждом блоке; повышенная сложность модели; увеличение времени обработки; необходимость в больших вычислительных ресурсах по сравнению с 2D-CNN.

Рисунок 9. Свёрточные фильтры и карты признаков автоматизированного экстрактора признаков на основе 2D-CNN (а) и 3D-CNN (b) для 24 обучающих гиперспектральных изображений (HSI) и 16 тестовых HSI.
Исходные гиперспектральные «кубы» данных с размерами 512 × 512 пикселей × 203 спектральных каналов(ширина × высота × спектральные каналы) были преобразованы в новое, менее размерное пространство данных: с помощью экстрактора признаков на основе 2D-CNN — до 16 × 16 пикселей × 64 фильтров (ширина × высота × свёрточные фильтры); с помощью экстрактора признаков на основе 3D-CNN — до 16 × 16 пикселей × 5 спектральных каналов × 64 фильтров (ширина × высота × спектральные каналы × свёрточные фильтры).
Сокращённые пространственные признаки (16 × 16) были сопоставлены со значениями свёрточных фильтров (случайный выбор из 64 единиц). Градиентная шкала отражает значения свёрточных фильтров.
В процессе обучения и валидации конвейера машинного обучения на 24 гиперспектральных изображениях (HSI) классификатор «случайный лес» (Random Forest) продемонстрировал наилучшие результаты как для модели 2D-CNN, так и для модели 3D-CNN. Точность составила 71% для 2D-CNN и 75% для 3D-CNN при 5-кратной кросс-валидации.
На рисунке 10a, b представлены результаты классификации на тестовом наборе данных (n = 16 HSI), где в качестве автоматических экстракторов признаков использовались модели 2D-CNN и 3D-CNN.
Точность тестирования модели 2D-CNN в точности совпала с точностью модели 3D-CNN — 50%.
Обе модели хорошо справились с обработкой данных от 7 августа, корректно классифицировав 3 из 4 гиперспектральных изображений (HSI). Однако результаты обработки данных от 29 августа оказались неудовлетворительными: модели ошибочно классифицировали 3 из 4 HSI.
В целом, половина тестовых изображений от 19 сентября и 8 октября была корректно отнесена к соответствующим группам — либо к категории «здоровые лозы», либо к категории «лозы, инфицированные GVCV».
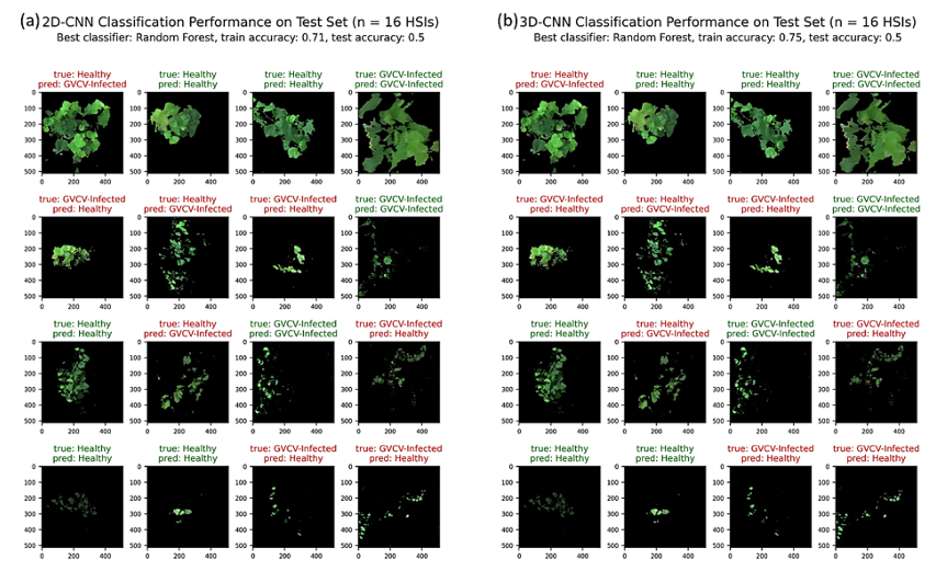
Рисунок 10. Эффективность классификации моделей 2D-CNN (а) и 3D-CNN (b) на выделенном тестовом наборе данных (n = 16 гиперспектральных изображений — HSI).
Наилучшим классификатором оказался подход на основе случайного леса (RF), продемонстрировавший: точность валидации 71% для модели 2D-CNN; точность валидации 75% для модели 3D-CNN.
Обе модели корректно классифицировали 50% из 16 HSI в тестовом наборе.
Подписи к изображениям указывают на истинные и прогнозируемые классы («здоровые лозы» в сравнении с «лозами, инфицированными GVCV»): зелёные подписи обозначают корректную классификацию; красные подписи обозначают ошибочную классификацию.
Порядок строк соответствует датам измерений: 7 августа; 29 августа; 19 сентября; 8 октября 2019 года.
4. Обсуждение
4.1. Эффективность различения отражательных спектров
При анализе объединённого набора данных были выявлены различия по полосам в диапазоне волн видимого спектра (VIS) — 500–620 нм. Эти различия подтвердились с уровнем достоверности 80 % и статистической значимостью p < 0,2.
При рассмотрении в динамике оказалось, что спектральные сигналы лоз, поражённых GVCV, лучше различимы в диапазоне волн VIS (449–461 нм, p < 0,1). При этом значения начинались с той же спектральной величины, но по мере увеличения тяжести инфекции прогрессивно возрастали по сравнению со значениями для здоровых растений (см. рисунок 6d).
Это явление связано с изменением состава пигментов листа, которые доминируют в видимом спектральном диапазоне [79]. Результат подтверждает нашу гипотезу и данные предыдущих исследований [80]: у больных растений концентрация пигментов снижается, листья хуже поглощают свет и, соответственно, отражают больше электромагнитной энергии в сторону датчика.
При этом на исследуемых стадиях у лоз не наблюдалось хлороза или пожелтения — область «красного края» спектра не смещалась в сторону более низких волн [73].
Что касается ближнего инфракрасного диапазона (NIR):
· различия между здоровыми лозами и лозами, поражёнными GVCV, чётко прослеживаются в диапазоне 900–940 нм (p < 0,1) на ранней стадии инфекции;
· однако в последующих спектральных измерениях этот паттерн исчезает и вновь едва заметно проявляется на поздней бессимптомной стадии;
· повышенный коэффициент отражения в NIR-диапазоне у лоз с GVCV подтверждает наши предположения о физиологических изменениях растений, связанных с уменьшением содержания воды в листьях;
· кроме того, после инфицирования разрушение клеточных структур и снижение плотности клеток также частично способствуют увеличению отражения в NIR-диапазоне [80].
Проблема «инверсии» значений в NIR-диапазоне для лоз с GVCV, зафиксированная в данных за 29 августа и 9 сентября, вероятно, связана с изменением угла съёмки: 7 августа вертикальный (надирный) угол съёмки позволил зафиксировать спектроскопические изображения почти всех новых побегов и молодых листьев — именно в этот период началась инфекция GVCV; при горизонтальных измерениях поражённые побеги и листья были скрыты до тех пор, пока инфекция не распространилась по всему растению на поздней стадии.
Угол съёмки также является проблемой при обнаружении болезней с помощью БПЛА (беспилотных летательных аппаратов), поскольку надирный угол съёмки не позволяет зафиксировать нижнюю часть кроны. Это особенно актуально для таких заболеваний, как грибок Corynespora cassicola, который развивается в нижней части растения [26].
4.2. Интерпретация анализа важности признаков
Что касается важности вегетационных индексов, для предварительного анализа была использована средняя уменьшенная примесь (MDI — Mean Decreased Impurity) на основе метода «случайного леса» (random-forest).
Среди распространённых вегетационных индексов, ориентированных на выявление болезней (VIs), наиболее отличительными на ранних стадиях были признаны: нормализованный индекс феофитизации (NPQI); индекс соотношения флуоресценции 1 (FRI₁); индекс отражения, связанный с увяданием растений (PSRI); индекс антоцианов (Ant_Gitelson).
На более поздних стадиях ключевым стал показатель, связанный с водным стрессом и температурой кроны (WSCT).
Более подробно:
· NPQI (значения 415 и 435 нм) оказался наиболее чувствительным к деградации хлорофилла с образованием феофитина [74].
· FRI₁ (значения 630 и 690 нм) — индикатор флуоресценции хлорофилла, тесно связанный с физиологическим состоянием фотосистемы II и устьичной проводимостью [70, 72]. Важно отметить, что флуоресценция хлорофилла положительно коррелирует с фотосинтезом в условиях стресса и отрицательно — в нормальных условиях [81].
· PSRI тесно связан со структурой каротиноидов и клеток мезофилла [63, 82].
· Ant_Gitelson (значения 550, 700 и 780 нм) тесно связан с содержанием антоцианов [52].
· WSCT (значения 850 и 970 нм) тесно связан с содержанием воды и температурой в кроне [77].
Предыдущие исследования также показали: важность NPQI для раннего выявления поражения оливковых деревьев бактерией Xylella fastidiosa (Xf) [83]; значимость FRI₁ для выявления соевых растений, испытывающих водный стресс [84], а также для оценки урожайности и качества ягод винограда [36]; критическую важность PSRI для характеристики спектров листьев арахиса, поражённых пятнистостью [85]; необходимость использования Ant_Gitelson для выявления вируса пятнистого увядания томатов (TSWV) у растений перца [86]; существенную роль индексов, связанных с содержанием воды, для более точного выявления цитрусовой бактериальной пятнистости [26].
Кроме того, при первом измерении датчик смог полностью и стабильно зафиксировать содержание феофитина, антоцианина и флуоресценции хлорофилла, изменённое у поражённых болезнью виноградных лоз. Полученные изображения оказались однородными (рисунки 3 и 4), что позволило успешно классифицировать их в сравнении со снимками здоровых лоз (рисунок 7f).
На рисунке 7f показано, что причиной нестабильности и слабой корреляции между результатами обучения и тестирования при гиперспектральных измерениях (данные от 29 августа и 19 сентября) стали значительные расхождения между значениями FRI₁ и PSRI на разных изображениях.
Возможно, флуоресценция хлорофилла, измеряемая с помощью FRI₁, в значительной степени зависит от условий освещённости и времени суток. Согласно одному исследованию [87], интенсивность флуоресцентного излучения и фотосинтеза наиболее сильно колеблется во второй половине дня, когда растения подвергаются воздействию высокой интенсивности солнечного света.
29 августа и 19 сентября мы измеряли спектры отражения в период с 14:00 до 15:00 (таблица 1).
Что касается вариаций PSRI, то при горизонтальном сканировании растения на уровне кроны удалось лишь частично зафиксировать изменения в содержании каротиноидов и структуре мезофилла в клетках и листьях [82, 88]. При этом пропорции этих изменений существенно различались от растения к растению.
Примечательно, что структурные вегетационные индексы (VI) не оказались полезными для спектральной классификации из-за схожести структуры кроны и окраски (то есть «зелёности») здоровых и поражённых растений в бессимптомный период.
4.3. Сравнение эффективности классификации
При сравнении эффективности классификации, основанной на вегетационных индексах (VI) и на пиксельных данных, оба метода показали сопоставимые результаты. В частности: точность 5-кратной кросс-валидации в модели, основанной на VI, составила от 82,13 % до 96,75 % (рис. 7f); в пиксельной модели точность варьировалась от 85,10 % до 95,30 % (рис. 8a–e).
Наши результаты также показали, что метод опорных векторов (SVM) лучше справляется с небольшими объёмами данных признаков при классификации по VI. SVM продемонстрировал эффективность, сопоставимую с классификатором «случайный лес» (RF) для наименьшей 2-признаковой модели при классификации по пикселям.
С другой стороны, классификатор RF оказался наиболее эффективным для данных отражения, которые были ортогонально преобразованы с помощью: метода главных компонент (PCA); ядерного метода главных компонент (Kernel-PCA).
Эти методы формируют пространство с большим количеством признаков. Это наглядно демонстрирует преимущество классификатора RF при работе с высокоразмерными данными: он использует случайный набор признаков на каждом этапе разделения дерева в «лесу», что позволяет сгладить вариативность признаков.
Многочисленные исследования, посвящённые патологическим и энтомологическим изменениям растительности, подтвердили, что: SVM эффективно моделирует VI, извлечённые из спектральных диапазонов [39, 89, 90]; классификатор RF демонстрирует стабильную и высокую эффективность при работе с преобразованными данными спектрального отражения [91–93].
Сравнение моделей на основе VI и пиксельных данных с моделью на основе изображений затруднено из-за различий в размеченных целях. Тем не менее для всех трёх подходов были использованы: одинаковые обучающие наборы данных; тестовые наборы данных (hold-out); единые конвейеры машинного обучения.
Это позволило получить целостное представление о задаче классификации.
С помощью автоматизированных экстракторов признаков 2D-CNN и 3D-CNN в модели на основе изображений были получены следующие результаты: точность 71 % и 75 % при 5-кратной кросс-валидации; точность 50 %при тестировании в обеих сетях.
Основная причина таких результатов — ограниченный объём выборки (40 изображений) при классификации на уровне изображений.
Ключевое отличие: методы на основе VI и пиксельных данных в основном учитывают спектральные признаки; модель на основе изображений одновременно извлекает совмещённые пространственно-спектральные признаки.
Пространственные признаки могли стать источником шума, поскольку в каждом изображении анализировались фрагментированные участки виноградной лозы, а не целые растения (см. рис. 3).
Анализ важности признаков подтвердил, что структура и морфология растений имеют большое значение для данной задачи классификации.
Все три подхода показали ограниченную успешность при классификации данных съёмки от 29 августа и 9 сентября. Высокая вариативность наборов данных на уровне кроны обусловлена: неполным учётом физиологических изменений в клетках листьев; отсутствием дополнительных данных о рассеянии электромагнитного излучения в прилегающей зоне.
5. Выводы
Надёжная, точная и неразрушающая методика критически важна для ранней идентификации заболеваний сельскохозяйственных культур, поскольку позволяет своевременно вмешаться и предотвратить распространение болезней на всём поле. В рамках данного исследования была изучена возможность использования гиперспектральных изображений, полученных с помощью дистанционного зондирования, в качестве неразрушающего метода для выявления виноградных лоз, заражённых вирусом GVCV на ранних, бессимптомных стадиях. С учётом всех факторов были сделаны следующие основные выводы:
1. Спектры отражения предоставили полезную информацию, которая была использована для определения набора оптимальных длин волн, позволяющих отличить заражённые GVCV лозы от здоровых на бессимптомной стадии. Ключевые диапазоны волн, обладающие различительной способностью, включают: 900–940 нм в ближнем инфракрасном диапазоне (NIR) — для лоз, инокулированных на 30-й день после посадки (DAS); 449–461 нм в видимом диапазоне (VIS) — для лоз, инокулированных на 90-й день после посадки (DAS); весь видимый диапазон 400–700 нм — при принятии более низкого уровня достоверности (90 %) и p-значения 0,1.
2. Экспериментальный анализ показал важность вегетационных индексов (VIs), связанных с изменениями пигментов, физиологических параметров и содержания воды в кроне. На ранних стадиях заражения GVCV наиболее информативными индексами оказались: NPQI; FRI₁; PSRI; Ant Gitelson.
На более поздних стадиях ключевым индексом для выявления вирусного заболевания стал WSCT.
Указанные индексы отражают изменения, происходящие при: деградации хлорофилла с образованием феофитина; флуоресценции хлорофилла; изменении структуры каротиноидов и клеток мезофилла; изменении уровня антоцианов; изменении содержания воды и температуры в кроне.
3. Производительность классификации моделей, основанных на вегетационных индексах (VI) и на пиксельных данных, была сопоставима на разных наборах данных. Метод опорных векторов (SVM) показал свою эффективность при классификации по VI в пространствах с меньшим количеством признаков, в то время как классификатор «случайный лес» (RF) продемонстрировал лучшие результаты при классификации по пикселям и изображениям в пространствах с большим количеством признаков. Все методы классификации оказались наиболее точными для лоз винограда в возрасте 30 и 90 дней после посадки (DAS) и показали ограниченную эффективность для лоз в возрасте 50 и 70 DAS.
4. При моделировании на уровне изображений автоматизированный экстрактор признаков 3D-CNN продемонстрировал многообещающие результаты по сравнению с экстрактором 2D-CNN в плане извлечения признаков из гиперспектральных кубов данных при ограниченном количестве образцов.
Результаты данного исследования могут помочь виноградарям, производителям вина, а также учёным, занимающимся патологией и энтомологией, в ранней идентификации первого ДНК-вирусного заболевания (GVCV) у лоз винограда — эффективным и неразрушающим способом. Кроме того, исследование демонстрирует потенциальные подходы к обработке и моделированию гиперспектральных изображений с учётом только спектральных признаков, только пространственных признаков и объединённых пространственно-спектральных признаков. Преимущества методов глубокого обучения были использованы при обработке цифровых изображений в сочетании с универсальностью традиционных методов машинного обучения при работе с ограниченным объёмом выборки.
18 февраля / 2026