Оставить заявку
Для заказа и получения более подробной информации оставьте заявку, наш менеджер свяжется с Вами!
Нажимая на кнопку, вы даете согласие на обработку персональных данных и соглашаетесь c политикой конфиденциальности
Синтетические данные в GeoAI: могут ли модели обучаться без реальных данных?
Аравинд Субраманиан 31 марта 2026 года

Геопространственный искусственный интеллект (GeoAI) зависит от данных. Чем больше примеров видит модель, тем лучше она распознаёт закономерности на спутниковых снимках, картах и данных сенсоров. Однако на практике качественных геопространственных обучающих данных не хватает. Для обучения современных моделей требуются тысячи или миллионы размеченных примеров, а создание такой разметки – процесс медленный и дорогостоящий. Аналитикам часто приходится вручную обводить здания, дороги или классы земного покрова на снимках – это называется аннотированием спутниковых изображений.
Даже если размеченные наборы данных существуют, они редко бывают идеальными. Эталонная информация может быть неполной или противоречивой, особенно когда снимки содержат облака, тени или имеют ограниченное разрешение. Проблемы, вызванные зашумлёнными или неточными метками, хорошо известны при анализе спутниковых снимков с несовершенными наземными данными. Сложность возрастает ещё больше для редких событий, таких как наводнения, разрушение инфраструктуры или последствия лесных пожаров. Эти события происходят недостаточно часто, чтобы создать большие размеченные наборы данных, но именно для таких сценариев необходимы надёжные системы GeoAI. В то же время правила конфиденциальности и ограничения доступа к данным сужают возможности обмена информацией – проблема, которая обсуждается в контексте применения ИИ для обработки геопространственных данных и GeoAI-приложений в экологической эпидемиологии.
Если сбор достаточного объёма реальных данных слишком медленный, дорогой или порой невозможный, возникает естественный вопрос: можем ли мы генерировать данные сами? Эта статья рассматривает, как синтетические среды и симулированные данные используются для обучения геопространственных ИИ-систем. В ней исследуется, когда синтетические данные помогают, когда не работают и как могут дополнять реальные наблюдения. Статья предназначена для геопространственных специалистов, специалистов по обработке данных и исследователей GeoAI, которые хотят получить практическое представление о перспективах и ограничениях синтетических данных в этой области.
Даже если размеченные наборы данных существуют, они редко бывают идеальными. Эталонная информация может быть неполной или противоречивой, особенно когда снимки содержат облака, тени или имеют ограниченное разрешение. Проблемы, вызванные зашумлёнными или неточными метками, хорошо известны при анализе спутниковых снимков с несовершенными наземными данными. Сложность возрастает ещё больше для редких событий, таких как наводнения, разрушение инфраструктуры или последствия лесных пожаров. Эти события происходят недостаточно часто, чтобы создать большие размеченные наборы данных, но именно для таких сценариев необходимы надёжные системы GeoAI. В то же время правила конфиденциальности и ограничения доступа к данным сужают возможности обмена информацией – проблема, которая обсуждается в контексте применения ИИ для обработки геопространственных данных и GeoAI-приложений в экологической эпидемиологии.
Если сбор достаточного объёма реальных данных слишком медленный, дорогой или порой невозможный, возникает естественный вопрос: можем ли мы генерировать данные сами? Эта статья рассматривает, как синтетические среды и симулированные данные используются для обучения геопространственных ИИ-систем. В ней исследуется, когда синтетические данные помогают, когда не работают и как могут дополнять реальные наблюдения. Статья предназначена для геопространственных специалистов, специалистов по обработке данных и исследователей GeoAI, которые хотят получить практическое представление о перспективах и ограничениях синтетических данных в этой области.

Что на самом деле означают синтетические данные в геопространственном контексте
В GeoAI синтетические данные – это не просто «фальшивые» изображения. Это данные, генерируемые компьютером в соответствии с географическими, физическими законами и моделями поведения человека. Цель – создать реалистичные обучающие примеры, когда реальных наблюдений недостаточно.
Один из распространённых подходов – построение симулированных городов и дорожных сетей, где целые городские среды создаются в 3D. Поскольку компьютер создаёт каждое здание, дерево и дорогу, точное местоположение каждого объекта изначально известно. Это означает, что каждый пиксель сопровождается идеальной меткой, что исключает необходимость ручной аннотации.
Другая форма – искусственные спутниковые снимки, генерируемые с помощью генеративных моделей, таких как синтез геопространственных изображений на основе GAN. Такие системы изучают визуальные закономерности из реальных спутниковых снимков и создают новые, напоминающие леса, города или сельскохозяйственные ландшафты.
Синтетические данные могут также поступать из физически обоснованных симуляций. Гидрологические модели имитируют движение воды по рельефу, а модели пожаров воспроизводят распространение огня в лесах. Примеры включают симуляции пожаров с помощью ИИ и гибридное гидрологическое моделирование «физика + ИИ», используемое для генерации реалистичных сценариев бедствий.
Четвёртая категория включает синтетические данные о мобильности, где виртуальные агенты перемещаются по симулированным городам, воспроизводя трафик и транспортные потоки. Такие агентно-ориентированные модели всё чаще используются в синтетических симуляциях мобильности для городского планирования.
На практике синтетические данные не предназначены для замены реальных наблюдений. Они предоставляют дополнительные обучающие примеры, позволяя моделям GeoAI изучать закономерности до того, как они столкнутся со сложностью реального мира.
Почему синтетические данные привлекательны для GeoAI
Синтетические данные привлекательны, потому что они решают многие проблемы, связанные с «узким местом» нехватки данных в GeoAI.
Во-первых, они позволяют исследовать редкие события. Такие катастрофы, как наводнения, землетрясения или разрушения инфраструктуры, случаются нечасто, поэтому для обучения моделей существует очень мало размеченных примеров. С помощью симуляции можно сгенерировать тысячи сценариев, позволяя моделям изучать закономерности экстремальных событий до того, как они произойдут. Этот подход активно исследуется в таких областях, как прогнозирование лесных пожаров с использованием синтетических данных и создание ИИ-систем для устойчивой к катастрофам инфраструктуры.
Во-вторых, синтетические среды позволяют проводить контролируемые эксперименты. Исследователи могут менять один параметр за раз (например, интенсивность осадков или крутизну склона) и наблюдать за реакцией модели. Такой уровень контроля невозможен в реальных условиях.
В-третьих, симуляции предоставляют изобилие меток. Поскольку виртуальный мир создаётся компьютером, каждый объект уже имеет известную идентичность, что исключает необходимость дорогостоящей ручной разметки.
Наконец, синтетические наборы данных поддерживают крупномасштабное предварительное обучение. Огромные симулированные датасеты могут научить модели общим визуальным закономерностям перед их тонкой настройкой на меньших реальных наборах данных – подход, широко используемый в конвейерах синтетических данных для физических ИИ-систем.
На практике синтетические данные действуют как тренировочный полигон, где модели GeoAI могут учиться до того, как столкнуться со сложностью реального мира.
Простой концептуальный пример
Рассмотрим простую задачу: обучение модели обнаружению затопленных зон на снимках с дронов. Такая система могла бы помочь аварийным службам быстро определять затопленные улицы или районы и планировать безопасные маршруты спасения.
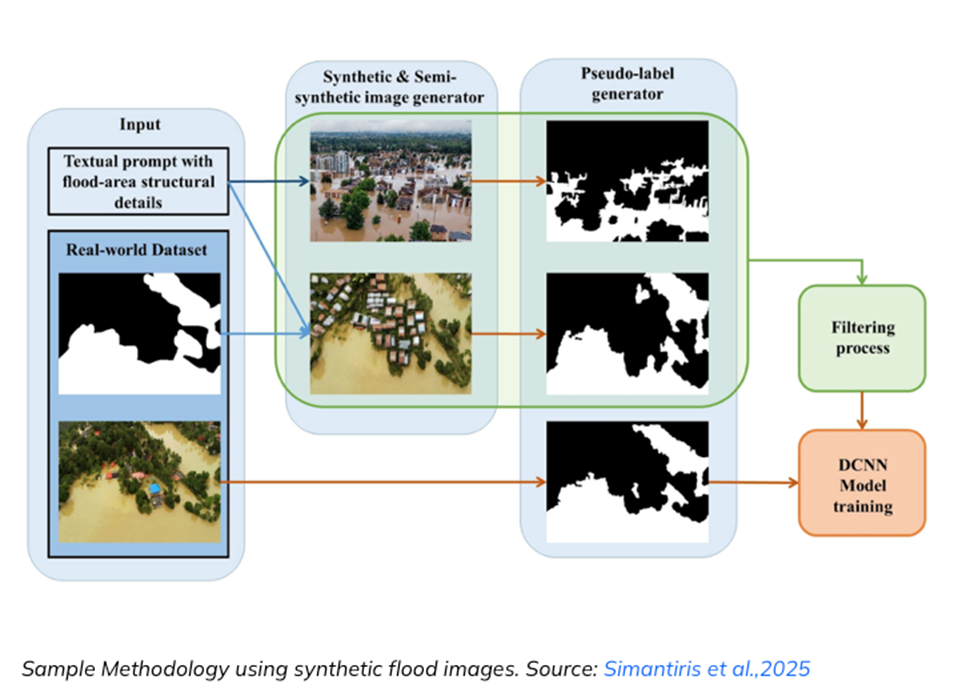
С реальными данными процесс идёт медленно. Сначала должно произойти наводнение, затем дроны должны сделать снимки, а аналитики – вручную разметить каждую затопленную зону. Создание большого обучающего набора данных может занять годы, и ошибки в разметке нередки.
Синтетические данные предлагают иной подход. Вместо ожидания катастрофы исследователи могут симулировать наводнения с помощью гидрологических моделей и виртуальных ландшафтов. Такие симуляции генерируют тысячи изображений, показывающих, как вода распространяется по местности в различных условиях. Поскольку среда создаётся компьютером, точное расположение воды изначально известно, то есть каждое изображение сопровождается идеальными метками.
Критический вопрос остаётся: распознает ли модель, обученная на симулированных наводнениях, реальные? Разрыв между симулированной и реальной средой – центральная проблема синтетических данных в GeoAI.
Критический вопрос остаётся: распознает ли модель, обученная на симулированных наводнениях, реальные? Разрыв между симулированной и реальной средой – центральная проблема синтетических данных в GeoAI.
Проблема разрыва между симуляцией и реальностью
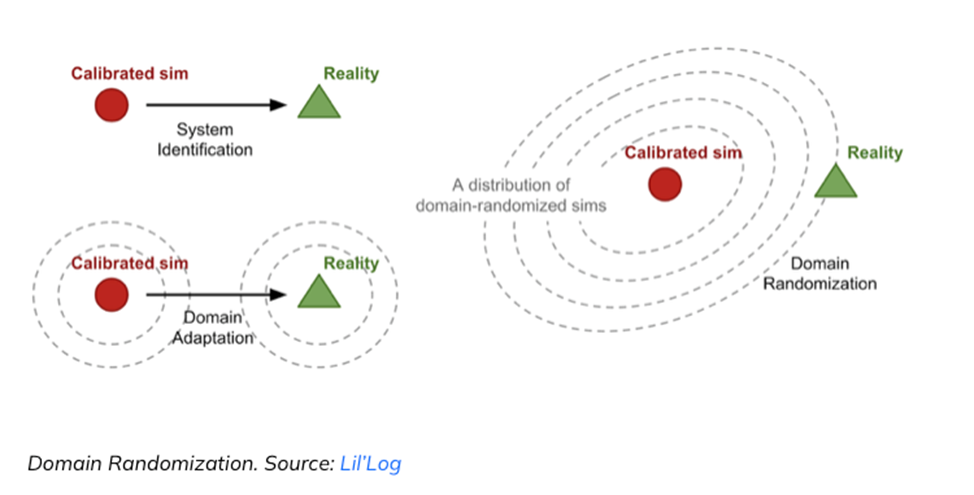
Самая большая проблема синтетических данных – это разрыв между симуляцией и реальностью (domain gap). Синтетические среды обычно чистые и контролируемые, в то время как реальный мир полон шума и непредсказуем. Это различие может привести к тому, что модели, обученные на симуляциях, будут давать сбои при применении к реальным снимкам.
Одна из причин – сенсорный и атмосферный шум. Реальные спутниковые снимки подвержены влиянию дымки, облаков, условий освещения и несовершенствам сенсоров. Симулированные изображения часто лишены этих искажений, создавая нереалистично чистые наборы данных. Исследования разрыва между симуляцией и реальностью подчёркивают, как модели, обученные на идеальных симуляциях, испытывают трудности при столкновении с реальным шумом сенсоров.
Другая проблема – отсутствие сложности. Симулированные среды часто представляют собой идеализированные города или ландшафты, в то время как реальные места содержат нерегулярные структуры, тени, растительный покров и износ инфраструктуры. Если симуляции опускают эти детали, модели могут изучать закономерности, которых не существует вне симулятора.
Существует также риск изучения артефактов симулятора. Модели могут полагаться на тонкие особенности, созданные графическим движком, вместо реальных географических признаков. Исследования, посвящённые разрыву между синтетическими и реальными снимками, показывают, как такие артефакты могут искажать поведение модели.
Чтобы уменьшить этот разрыв, исследователи часто применяют такие методы, как доменная рандомизация (domain randomization) и адаптация домена (domain adaptation), намеренно добавляя шум и изменчивость, чтобы модели изучали более устойчивые признаки.
Чтобы уменьшить этот разрыв, исследователи часто применяют такие методы, как доменная рандомизация (domain randomization) и адаптация домена (domain adaptation), намеренно добавляя шум и изменчивость, чтобы модели изучали более устойчивые признаки.
Где синтетические данные действительно хорошо работают
Несмотря на проблему разрыва, синтетические данные уже успешно применяются в нескольких областях GeoAI при условии осторожного использования.
Одно из наиболее эффективных применений – предварительное обучение и аугментация редких классов. Например, моделям для обнаружения ущерба от ураганов часто не хватает больших размеченных наборов данных. Синтетическая аугментация может сгенерировать тысячи вариаций повреждённых зданий, помогая моделям изучать закономерности до того, как они столкнутся с реальными снимками катастроф.
Синтетические среды также хорошо работают для изучения структурных закономерностей, таких как дорожные сети. Обучение на симулированных городских планах позволяет моделям понимать, как дороги обычно соединяются и пересекаются, что улучшает результаты извлечения дорог из спутниковых снимков в быстрорастущих городах.
Одно из наиболее эффективных применений – предварительное обучение и аугментация редких классов. Например, моделям для обнаружения ущерба от ураганов часто не хватает больших размеченных наборов данных. Синтетическая аугментация может сгенерировать тысячи вариаций повреждённых зданий, помогая моделям изучать закономерности до того, как они столкнутся с реальными снимками катастроф.
Синтетические среды также хорошо работают для изучения структурных закономерностей, таких как дорожные сети. Обучение на симулированных городских планах позволяет моделям понимать, как дороги обычно соединяются и пересекаются, что улучшает результаты извлечения дорог из спутниковых снимков в быстрорастущих городах.
Ещё одно важное применение – моделирование устойчивости инфраструктуры. Инженеры всё чаще создают цифровые двойники городов и симулируют наводнения, землетрясения или отказы инфраструктуры для выявления уязвимых объектов до наступления катастроф.
Синтетические данные также показали высокие результаты в системах восприятия. NVIDIA продемонстрировала, что симулированные изображения могут улучшить обнаружение удалённых транспортных средств в системах автономного вождения, достигнув значительного прироста точности в экспериментах по обнаружению дальних объектов.
Синтетические данные также показали высокие результаты в системах восприятия. NVIDIA продемонстрировала, что симулированные изображения могут улучшить обнаружение удалённых транспортных средств в системах автономного вождения, достигнув значительного прироста точности в экспериментах по обнаружению дальних объектов.
Наконец, синтетическая аугментация помогает в картографировании сложных городских сред. Такие методы, как извлечение неформальных поселений с помощью SAMLoRA, используют небольшие реальные наборы данных в сочетании с генерируемыми примерами для улучшения обнаружения плотных неформальных кварталов.
В этих случаях синтетические данные не заменяют реальные наблюдения, а усиливают их.
В этих случаях синтетические данные не заменяют реальные наблюдения, а усиливают их.
Гибридное будущее: сочетание симуляции и реальности
Будущее GeoAI, вероятно, будет основываться не на синтетических или реальных данных по отдельности, а на их сочетании. Наиболее эффективные системы всё чаще объединяют оба подхода. Синтетические данные обеспечивают масштаб и гибкость, в то время как реальные данные удерживают модели в рамках реальности.
Один из распространённых подходов – тонкая настройка моделей, предварительно обученных на синтетических данных. Модели сначала обучаются на больших синтетических наборах для изучения общих визуальных закономерностей, а затем дообучаются на меньших реальных датасетах. Эта стратегия снижает потребность в больших размеченных наборах данных и улучшает производительность в реальных условиях.
Один из распространённых подходов – тонкая настройка моделей, предварительно обученных на синтетических данных. Модели сначала обучаются на больших синтетических наборах для изучения общих визуальных закономерностей, а затем дообучаются на меньших реальных датасетах. Эта стратегия снижает потребность в больших размеченных наборах данных и улучшает производительность в реальных условиях.
Ещё одно перспективное направление – физико-информированные нейронные сети (physics-informed neural networks, PINN), которые включают физические ограничения непосредственно в процесс обучения. Такие модели обеспечивают согласованность предсказаний с реальными процессами, такими как движение жидкости или сохранение энергии.
Исследователи также изучают обучение с петлёй симуляции (simulation-in-the-loop), где модели взаимодействуют с симуляторами во время обучения и постоянно улучшаются за счёт обратной связи. В сочетании с методами адаптации домена, которые помогают моделям переносить знания из синтетической среды в реальную, эти подходы направлены на преодоление разрыва между симуляцией и реальностью.
На практике будущее GeoAI – это не «синтетика против реальности», а «синтетика плюс реальность».
Исследователи также изучают обучение с петлёй симуляции (simulation-in-the-loop), где модели взаимодействуют с симуляторами во время обучения и постоянно улучшаются за счёт обратной связи. В сочетании с методами адаптации домена, которые помогают моделям переносить знания из синтетической среды в реальную, эти подходы направлены на преодоление разрыва между симуляцией и реальностью.
На практике будущее GeoAI – это не «синтетика против реальности», а «синтетика плюс реальность».
Что это значит для будущего GeoAI
Синтетические данные становятся важной частью инструментария GeoAI. Они позволяют исследователям генерировать обучающие данные для редких событий, тестировать новые сценарии и исследовать среды, которые трудно или невозможно наблюдать в реальном мире. Симулированные среды также открывают путь к новым типам систем, которые могут экспериментировать с городским планированием, реагированием на катастрофы или экологическими изменениями до того, как решения будут реализованы.
В то же время синтетические данные не могут заменить реальность. Модели должны оставаться привязанными к реальным наблюдениям и проверяться на соответствие реальным измерениям. Если обучение слишком сильно полагается на симулированные среды, модели рискуют оторваться от сложности и непредсказуемости реальной географии.
В то же время синтетические данные не могут заменить реальность. Модели должны оставаться привязанными к реальным наблюдениям и проверяться на соответствие реальным измерениям. Если обучение слишком сильно полагается на симулированные среды, модели рискуют оторваться от сложности и непредсказуемости реальной географии.
Будущие системы GeoAI, вероятно, будут объединять симуляции, физические модели и реальные данные в интегрированные среды, где планировщики и исследователи смогут безопасно проверять идеи перед их практическим применением. Такие системы облегчат изучение редких катастроф, оценку устойчивости инфраструктуры и исследование того, как города реагируют на экологические изменения.
Синтетические данные расширяют то, что мы можем себе представить и смоделировать. Реальные данные удерживают эти симуляции в рамках истины. Если мы ответственно объединим то и другое, GeoAI поможет нам не только понимать мир, но и готовиться к будущему, которое ещё не наступило.
Синтетические данные расширяют то, что мы можем себе представить и смоделировать. Реальные данные удерживают эти симуляции в рамках истины. Если мы ответственно объединим то и другое, GeoAI поможет нам не только понимать мир, но и готовиться к будущему, которое ещё не наступило.
Дополнительные ресурсы
- YouTube: Keynote – Synthetic Data for Geospatial AI (видео)
- YouTube: Simulation-to-Reality Transfer for Geospatial AI (видео)
- Taylor & Francis: Special Issue on Synthetic Data in Geospatial AI
- ScienceDirect: Synthetic Data Generation for Earth Observation
- Meegle: Synthetic Data for Geospatial Analysis (обзор)
01 апреля/ 2026