Оставить заявку
Для заказа и получения более подробной информации оставьте заявку, наш менеджер свяжется с Вами!
Нажимая на кнопку, вы даете согласие на обработку персональных данных и соглашаетесь c политикой конфиденциальности
Спектральная визуализация с использованием глубокого обучения
Longqian Huang1, Ruichen Luo2, Xu Liu 1 and Xiang Hao 3,4
Аннотация
Цель спектральной съёмки — зафиксировать спектральную сигнатуру объекта. Традиционный метод сканирования при спектральной съёмке имеет два существенных недостатка: большой объём системы и низкую скорость получения изображений для обширных сцен.
В отличие от него, вычислительные методы спектральной съёмки позволяют уменьшить объём системы за счёт использования вычислительных мощностей, однако по‑прежнему требуют значительного времени на итеративную реконструкцию спектра.
В последнее время в вычислительную спектральную съёмку внедряются методы глубокого обучения. Они демонстрируют: высокую скорость реконструкции; отличное качество реконструкции; потенциал для существенного уменьшения объёма системы.
В данной статье мы рассматриваем современные методы вычислительной спектральной съёмки с применением глубокого обучения. В зависимости от используемых для кодирования свойств света эти методы подразделяются на: методы с амплитудным кодированием; методы с фазовым кодированием; методы с кодированием по длине волны.
Для стимулирования дальнейших исследований мы также систематизировали общедоступные спектральные наборы данных.
В отличие от него, вычислительные методы спектральной съёмки позволяют уменьшить объём системы за счёт использования вычислительных мощностей, однако по‑прежнему требуют значительного времени на итеративную реконструкцию спектра.
В последнее время в вычислительную спектральную съёмку внедряются методы глубокого обучения. Они демонстрируют: высокую скорость реконструкции; отличное качество реконструкции; потенциал для существенного уменьшения объёма системы.
В данной статье мы рассматриваем современные методы вычислительной спектральной съёмки с применением глубокого обучения. В зависимости от используемых для кодирования свойств света эти методы подразделяются на: методы с амплитудным кодированием; методы с фазовым кодированием; методы с кодированием по длине волны.
Для стимулирования дальнейших исследований мы также систематизировали общедоступные спектральные наборы данных.
Введение
Благодаря возможности получать уникальную информацию в пространственной и спектральной областях, технология спектральной съёмки находит широкое применение в следующих сферах: дистанционное зондирование [1]; медицинская диагностика [2]; биомедицинская инженерия [3]; археология и реставрация произведений искусства [4]; контроль качества продуктов питания [5].
Традиционные методы спектральной съёмки включают: сканирование «щёткой» (whiskbroom scanning); сканирование «совком» (pushbroom scanning); сканирование по длине волны (wavelength scanning).
Сканирование «щёткой» выполняется пиксель за пикселем. Широко известный пример — авиационный спектрометр видимого и инфракрасного диапазона (Airborne Visible/Infrared Imaging Spectrometer) [6, 7], в котором метод «щётки» реализован на самолёте для дистанционного зондирования Земли.
Система сканирования «совком» использует входную щель и формирует изображение построчно. В эксперименте по сбору гиперспектральных цифровых изображений (Hyperspectral Digital Imagery Collection Experiment instrument) [8, 9] применена оптика съёмки «совком» с призменным спектрометром, что обеспечивает хорошие возможности для дистанционного зондирования.
Методы сканирования по длине волны позволяют получать спектральные кубические изображения путём: замены узкополосных фильтров перед объективом камеры; использования электронно‑перестраиваемых фильтров [10, 11].
Эти типичные методы сканирующей спектральной съёмки проиллюстрированы на рис. 1.
Однако традиционные методы сканирования имеют существенный недостаток: низкую скорость получения спектральных изображений из‑за затратного по времени механизма сканирования.
Как следствие, они неприменимы для обширных сцен или динамической съёмки. Чтобы решить эту проблему, исследователи начали разрабатывать методы спектральной съёмки в одно мгновение (snapshot spectral imaging) [12].
Первые попытки включали: интегральную полевую спектрометрию; мультиспектральное расщепление пучка; спектрометр с воспроизведением изображения (image‑replicating imaging spectrometer), — как указано в источнике [12].
Эти методы позволяют получать мультиспектральные изображения за счёт расщепления света, однако имеют два ограничения: не обеспечивают получение большого числа спектральных каналов; требуют громоздких оптических систем.
С развитием теории сжатого восприятия (compressed‑sensing, CS) [13, 14] компрессионная спектральная съёмка привлекает всё большее внимание исследователей благодаря изящному сочетанию оптики, математики и теории оптимизации.
Этот подход позволяет проводить спектральную съёмку с использованием меньшего числа измерений, что особенно важно в условиях ограниченных ресурсов.
Методы компрессионной спектральной съёмки зачастую применяют кодирующую апертуру для блокировки или фильтрации входного светового поля — так называемый процесс кодирования в цепочке сжатого восприятия. Как следует из названия, этот процесс выполняет функцию сжатия информации. Он отличается гибкостью в проектировании и обеспечивает предварительные данные для последующей реконструкции.
В отличие от аппаратного кодирования, процесс декодирования требует вычислительных операций с использованием специально разработанных алгоритмов.
Традиционный подход к реконструкции является итеративным: он использует данные измерений процесса кодирования и другие предварительные сведения для восстановления изображения. В результате процедура декодирования требует значительных вычислительных ресурсов и может занимать от нескольких минут до нескольких часов для реконструкции спектра.
Кроме того, проблема ухудшения качества при использовании меньшего числа измерений также ограничивает применение этого метода в условиях ограниченных ресурсов.
Традиционные методы спектральной съёмки включают: сканирование «щёткой» (whiskbroom scanning); сканирование «совком» (pushbroom scanning); сканирование по длине волны (wavelength scanning).
Сканирование «щёткой» выполняется пиксель за пикселем. Широко известный пример — авиационный спектрометр видимого и инфракрасного диапазона (Airborne Visible/Infrared Imaging Spectrometer) [6, 7], в котором метод «щётки» реализован на самолёте для дистанционного зондирования Земли.
Система сканирования «совком» использует входную щель и формирует изображение построчно. В эксперименте по сбору гиперспектральных цифровых изображений (Hyperspectral Digital Imagery Collection Experiment instrument) [8, 9] применена оптика съёмки «совком» с призменным спектрометром, что обеспечивает хорошие возможности для дистанционного зондирования.
Методы сканирования по длине волны позволяют получать спектральные кубические изображения путём: замены узкополосных фильтров перед объективом камеры; использования электронно‑перестраиваемых фильтров [10, 11].
Эти типичные методы сканирующей спектральной съёмки проиллюстрированы на рис. 1.
Однако традиционные методы сканирования имеют существенный недостаток: низкую скорость получения спектральных изображений из‑за затратного по времени механизма сканирования.
Как следствие, они неприменимы для обширных сцен или динамической съёмки. Чтобы решить эту проблему, исследователи начали разрабатывать методы спектральной съёмки в одно мгновение (snapshot spectral imaging) [12].
Первые попытки включали: интегральную полевую спектрометрию; мультиспектральное расщепление пучка; спектрометр с воспроизведением изображения (image‑replicating imaging spectrometer), — как указано в источнике [12].
Эти методы позволяют получать мультиспектральные изображения за счёт расщепления света, однако имеют два ограничения: не обеспечивают получение большого числа спектральных каналов; требуют громоздких оптических систем.
С развитием теории сжатого восприятия (compressed‑sensing, CS) [13, 14] компрессионная спектральная съёмка привлекает всё большее внимание исследователей благодаря изящному сочетанию оптики, математики и теории оптимизации.
Этот подход позволяет проводить спектральную съёмку с использованием меньшего числа измерений, что особенно важно в условиях ограниченных ресурсов.
Методы компрессионной спектральной съёмки зачастую применяют кодирующую апертуру для блокировки или фильтрации входного светового поля — так называемый процесс кодирования в цепочке сжатого восприятия. Как следует из названия, этот процесс выполняет функцию сжатия информации. Он отличается гибкостью в проектировании и обеспечивает предварительные данные для последующей реконструкции.
В отличие от аппаратного кодирования, процесс декодирования требует вычислительных операций с использованием специально разработанных алгоритмов.
Традиционный подход к реконструкции является итеративным: он использует данные измерений процесса кодирования и другие предварительные сведения для восстановления изображения. В результате процедура декодирования требует значительных вычислительных ресурсов и может занимать от нескольких минут до нескольких часов для реконструкции спектра.
Кроме того, проблема ухудшения качества при использовании меньшего числа измерений также ограничивает применение этого метода в условиях ограниченных ресурсов.
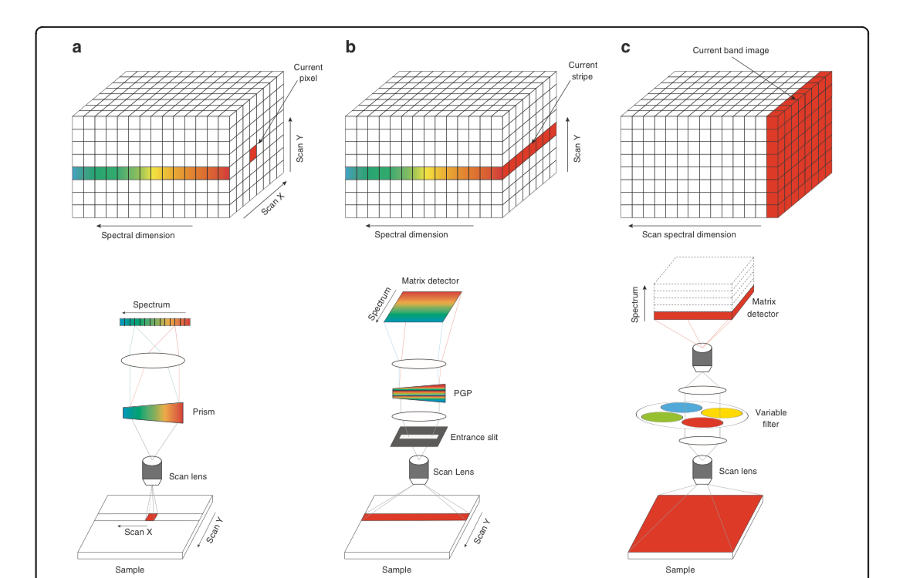
Рис. 1. Типичные методы сканирующей спектральной съёмки:
a) сканирование «щёткой» (whiskbroom);
b) сканирование «совком» (pushbroom). ПГП — призма‑решётка‑призма (prism‑grating‑prism, PGP);
c) сканирование по длине волны (wavelength scan).
Хотя использование кодирующей апертуры для амплитудного кодирования продемонстрировало возможность проведения спектральной съёмки с меньшим числом измерений, сниженный световой поток и большой объём системы делают этот метод непригодным для практического применения.
Чтобы преодолеть эти недостатки, была разработана фазово‑кодированная спектральная съёмка [15, 16]. Её основная цель — повысить световой поток и уменьшить объём системы.
Ключевая идея метода заключается в применении тщательно спроектированного тонкого дифракционного оптического элемента для управления фазой входного светового потока. Это воздействие влияет на спектры в процессе дифракции.
Для восстановления спектров, моделируемых в рамках сложного процесса дифракции, требуются мощные методы глубокого обучения.
Исследователи в области компьютерной графики также стремятся оптимизировать реконструкцию спектров, поскольку при рендеринге освещения сцены или отображении виртуального объекта на мониторе использование спектров предпочтительнее, чем троек RGB.
В ранних работах [17–19] спектр получали из тройки RGB, однако эта задача может оказаться некорректно поставленной: она допускает неединственное решение и приводит к отрицательным значениям спектра.
В более поздних исследованиях были предложены более эффективные методы, такие как: подбор базисных функций [20]; обучение по словарю [21].
Последний метод опирается на гиперспектральный набор данных, но по‑прежнему сталкивается с проблемой длительной процедуры подбора весовых коэффициентов.
Как показано в статистическом исследовании гиперспектральных изображений [22], спектры в пределах фрагмента изображения коррелируют между собой. Тем не менее пиксельные методы не позволяют использовать информацию о корреляции в спектральном кубическом массиве данных. В связи с этим ожидается появление эффективных алгоритмов извлечения признаков из фрагментов изображения.
Поиск точного и быстрого метода преобразования RGB в спектры стимулировал развитие методов с кодированием по длине волны. Исследователи расширили набор RGB‑фильтров до множества специально разработанных широкополосных фильтров для детального кодирования по длине волны. При этом возникает потребность в надёжном алгоритме декодирования.
Выполнение таких сложных вычислительных задач — как раз сфера применения глубокого обучения.
Чтобы снизить высокие вычислительные затраты, присущие вышеупомянутым методам, в качестве альтернативы было предложено применение алгоритмов глубокого обучения. Они позволяют изучать пространственно‑спектральные априорные данные и выполнять реконструкцию спектров.
Методы глубокого обучения обеспечивают более быструю и точную реконструкцию по сравнению с итеративными подходами, поэтому хорошо подходят для задач восстановления спектров.
В последние годы во многих исследованиях в рамках систем спектральной съёмки использовались модели глубокого обучения (в частности, свёрточные нейронные сети — CNN). Такие решения продемонстрировали повышение скорости и качества реконструкции [15, 16, 23–25].
В этом обзоре мы проследим эволюцию спектральной съёмки с применением инструментов глубокого обучения, а также обозначим перспективные направления развития вычислительных систем спектральной съёмки на базе технологий глубокого обучения.
В последующих разделах мы:
Наконец, в разделе «Выводы и перспективные направления» (Conclusions and Future Directions) мы обобщим методы спектральной съёмки с применением глубокого обучения и поделимся своими соображениями о будущем этой области.
Спектральная визуализация с амплитудным кодированием
Методы с амплитудным кодированием используют кодированную апертуру и дисперсионные элементы для компрессионной спектральной визуализации. Классической системой в этой области является кодированный апертурный спектральный снимок (CASSI — coded aperture snapshot spectral imager).
На сегодняшний день существует четыре архитектуры CASSI, основанные на различных способах пространственно‑спектральной модуляции, как показано на рис. 2.
1. Первая предложенная архитектура — CASSI с двойным диспергатором (DD‑CASSI, dual disperser CASSI). Она состоит из двух дисперсионных элементов для спектрального сдвига, между которыми расположена кодированная апертура.
2. CASSI с одиночным диспергатором (SD‑CASSI, single‑dispersive CASSI) — более поздняя разработка. В ней используется один дисперсионный элемент, размещённый за кодированной апертурой.
3. Снимковый цветной компрессионный спектральный визуализатор (SCCSI, snapshot colored compressive spectral imager) также использует кодированную апертуру и дисперсионный элемент, но размещает кодированную апертуру за дисперсионным элементом.
4. Архитектура CASSI с пространственно‑спектральной модуляцией (SS‑CASSI, spatial‑spectral CASSI) по сравнению с SCCSI, в которой к сенсору камеры прикрепляется цветная кодированная апертура (или массив цветных фильтров), добавляет гибкость в размещении кодированной апертуры между спектральной плоскостью и плоскостью сенсора. Это увеличивает сложность модели кодированной апертуры, что может способствовать повышению производительности системы.
Некоторые методы компрессионной спектральной визуализации на основе глубокого обучения показали лучшие результаты при использовании архитектуры SS‑CASSI [30, 31].
Модель кодированной апертуры
Поскольку большинство работ основано на системе SD‑CASSI, мы приведём подробное описание процесса формирования изображения в SD‑CASSI. Процедура формирования изображения отличается для других архитектур CASSI (см. рис. 2), однако ключевые процессы (векторзация, дискретизация и др.) остаются теми же. За подробным описанием моделей DD‑CASSI, SCCSI и SS‑CASSI мы отсылаем читателя к источникам [26, 28, 29] соответственно.
На момент предложения SD‑CASSI кодированная апертура имела шаблон «блок/разблок» (block–unblock pattern), который впоследствии был расширен до цветного шаблона (в источнике [32]). Для общности в наших выкладках мы будем использовать цветную кодированную апертуру.
Рассмотрим сцену с спектральной плотностью f(x,y,λ) и проследим её путь в системе SD‑CASSI:
1. Сначала она встречает кодированную апертуру с коэффициентом пропускания T(x,y,λ).
2. Затем происходит сдвиг (shearing) за счёт дисперсионного элемента (предположим, по оси x).
3. В итоге излучение попадает на матрицу детекторов.
Весь процесс иллюстрирует рис. 3.
Спектральная плотность перед детектором формулируется как…
a) сканирование «щёткой» (whiskbroom);
b) сканирование «совком» (pushbroom). ПГП — призма‑решётка‑призма (prism‑grating‑prism, PGP);
c) сканирование по длине волны (wavelength scan).
Хотя использование кодирующей апертуры для амплитудного кодирования продемонстрировало возможность проведения спектральной съёмки с меньшим числом измерений, сниженный световой поток и большой объём системы делают этот метод непригодным для практического применения.
Чтобы преодолеть эти недостатки, была разработана фазово‑кодированная спектральная съёмка [15, 16]. Её основная цель — повысить световой поток и уменьшить объём системы.
Ключевая идея метода заключается в применении тщательно спроектированного тонкого дифракционного оптического элемента для управления фазой входного светового потока. Это воздействие влияет на спектры в процессе дифракции.
Для восстановления спектров, моделируемых в рамках сложного процесса дифракции, требуются мощные методы глубокого обучения.
Исследователи в области компьютерной графики также стремятся оптимизировать реконструкцию спектров, поскольку при рендеринге освещения сцены или отображении виртуального объекта на мониторе использование спектров предпочтительнее, чем троек RGB.
В ранних работах [17–19] спектр получали из тройки RGB, однако эта задача может оказаться некорректно поставленной: она допускает неединственное решение и приводит к отрицательным значениям спектра.
В более поздних исследованиях были предложены более эффективные методы, такие как: подбор базисных функций [20]; обучение по словарю [21].
Последний метод опирается на гиперспектральный набор данных, но по‑прежнему сталкивается с проблемой длительной процедуры подбора весовых коэффициентов.
Как показано в статистическом исследовании гиперспектральных изображений [22], спектры в пределах фрагмента изображения коррелируют между собой. Тем не менее пиксельные методы не позволяют использовать информацию о корреляции в спектральном кубическом массиве данных. В связи с этим ожидается появление эффективных алгоритмов извлечения признаков из фрагментов изображения.
Поиск точного и быстрого метода преобразования RGB в спектры стимулировал развитие методов с кодированием по длине волны. Исследователи расширили набор RGB‑фильтров до множества специально разработанных широкополосных фильтров для детального кодирования по длине волны. При этом возникает потребность в надёжном алгоритме декодирования.
Выполнение таких сложных вычислительных задач — как раз сфера применения глубокого обучения.
Чтобы снизить высокие вычислительные затраты, присущие вышеупомянутым методам, в качестве альтернативы было предложено применение алгоритмов глубокого обучения. Они позволяют изучать пространственно‑спектральные априорные данные и выполнять реконструкцию спектров.
Методы глубокого обучения обеспечивают более быструю и точную реконструкцию по сравнению с итеративными подходами, поэтому хорошо подходят для задач восстановления спектров.
В последние годы во многих исследованиях в рамках систем спектральной съёмки использовались модели глубокого обучения (в частности, свёрточные нейронные сети — CNN). Такие решения продемонстрировали повышение скорости и качества реконструкции [15, 16, 23–25].
В этом обзоре мы проследим эволюцию спектральной съёмки с применением инструментов глубокого обучения, а также обозначим перспективные направления развития вычислительных систем спектральной съёмки на базе технологий глубокого обучения.
В последующих разделах мы:
- Сначала рассмотрим методы компрессионной спектральной съёмки с использованием глубокого обучения, реализующие амплитудное кодирование посредством кодирующих апертур («Амплитудно‑кодированная спектральная съёмка»).
- Затем представим фазово‑кодированные методы, в которых применяются дифракционные оптические элементы (ДОЭ, diffractive optical element, DOE, или рассеиватели) («Фазово‑кодированная спектральная съёмка»).
- В разделе «Спектральная съёмка с кодированием по длине волны» (Wavelength‑coded Spectral Imaging) познакомим с методами, использующими RGB‑ или широкополосные оптические фильтры для кодирования по длине волны, а также применяющими глубокие нейронные сети для реконструкции спектров.
- Чтобы стимулировать дальнейшие исследования в области обучаемой спектральной съёмки, мы систематизировали существующие спектральные наборы данных и метрики оценки («Наборы данных для спектральной съёмки»).
Наконец, в разделе «Выводы и перспективные направления» (Conclusions and Future Directions) мы обобщим методы спектральной съёмки с применением глубокого обучения и поделимся своими соображениями о будущем этой области.
Спектральная визуализация с амплитудным кодированием
Методы с амплитудным кодированием используют кодированную апертуру и дисперсионные элементы для компрессионной спектральной визуализации. Классической системой в этой области является кодированный апертурный спектральный снимок (CASSI — coded aperture snapshot spectral imager).
На сегодняшний день существует четыре архитектуры CASSI, основанные на различных способах пространственно‑спектральной модуляции, как показано на рис. 2.
1. Первая предложенная архитектура — CASSI с двойным диспергатором (DD‑CASSI, dual disperser CASSI). Она состоит из двух дисперсионных элементов для спектрального сдвига, между которыми расположена кодированная апертура.
2. CASSI с одиночным диспергатором (SD‑CASSI, single‑dispersive CASSI) — более поздняя разработка. В ней используется один дисперсионный элемент, размещённый за кодированной апертурой.
3. Снимковый цветной компрессионный спектральный визуализатор (SCCSI, snapshot colored compressive spectral imager) также использует кодированную апертуру и дисперсионный элемент, но размещает кодированную апертуру за дисперсионным элементом.
4. Архитектура CASSI с пространственно‑спектральной модуляцией (SS‑CASSI, spatial‑spectral CASSI) по сравнению с SCCSI, в которой к сенсору камеры прикрепляется цветная кодированная апертура (или массив цветных фильтров), добавляет гибкость в размещении кодированной апертуры между спектральной плоскостью и плоскостью сенсора. Это увеличивает сложность модели кодированной апертуры, что может способствовать повышению производительности системы.
Некоторые методы компрессионной спектральной визуализации на основе глубокого обучения показали лучшие результаты при использовании архитектуры SS‑CASSI [30, 31].
Модель кодированной апертуры
Поскольку большинство работ основано на системе SD‑CASSI, мы приведём подробное описание процесса формирования изображения в SD‑CASSI. Процедура формирования изображения отличается для других архитектур CASSI (см. рис. 2), однако ключевые процессы (векторзация, дискретизация и др.) остаются теми же. За подробным описанием моделей DD‑CASSI, SCCSI и SS‑CASSI мы отсылаем читателя к источникам [26, 28, 29] соответственно.
На момент предложения SD‑CASSI кодированная апертура имела шаблон «блок/разблок» (block–unblock pattern), который впоследствии был расширен до цветного шаблона (в источнике [32]). Для общности в наших выкладках мы будем использовать цветную кодированную апертуру.
Рассмотрим сцену с спектральной плотностью f(x,y,λ) и проследим её путь в системе SD‑CASSI:
1. Сначала она встречает кодированную апертуру с коэффициентом пропускания T(x,y,λ).
2. Затем происходит сдвиг (shearing) за счёт дисперсионного элемента (предположим, по оси x).
3. В итоге излучение попадает на матрицу детекторов.
Весь процесс иллюстрирует рис. 3.
Спектральная плотность перед детектором формулируется как…
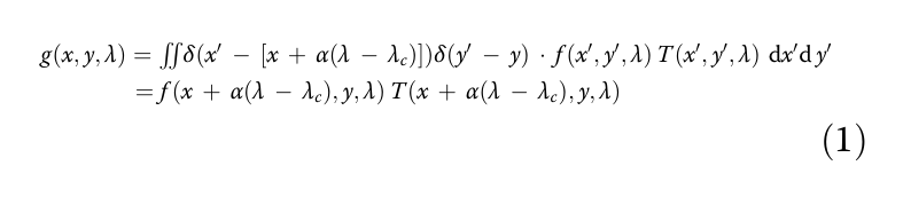
где дельта‑функция описывает спектральное рассеивание, вносимое дисперсионным элементом (таким как призмы или дифракционные решётки).
Параметр α — калибровочный коэффициент, а λc — центральная длина волны дисперсии.
Поскольку на детекторе мы можем измерять только интенсивность, результатом измерения должен быть интеграл по длине волны:
Параметр α — калибровочный коэффициент, а λc — центральная длина волны дисперсии.
Поскольку на детекторе мы можем измерять только интенсивность, результатом измерения должен быть интеграл по длине волны:
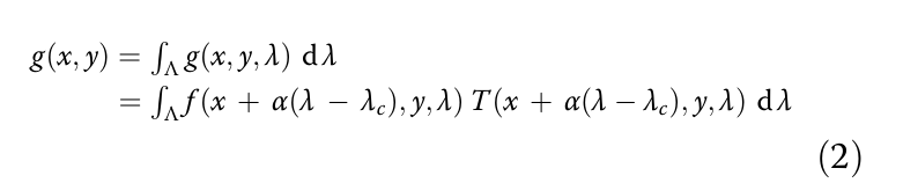
где Λ — диапазон спектра.
Далее мы дискретизируем уравнение (2). Обозначим Δ как размер пикселя детектора (по осям x и y), а размер квадратного пикселя кодированной апертуры примем равным Δcode=qΔ, где q≥1.
Тогда шаблон кода представляется в виде пространственного массива его пикселей:
Далее мы дискретизируем уравнение (2). Обозначим Δ как размер пикселя детектора (по осям x и y), а размер квадратного пикселя кодированной апертуры примем равным Δcode=qΔ, где q≥1.
Тогда шаблон кода представляется в виде пространственного массива его пикселей:
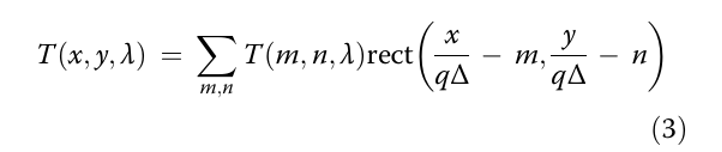
В конечном итоге сигналы в пределах области пикселя будут накапливаться в процессе дискретизации (сэмплирования):
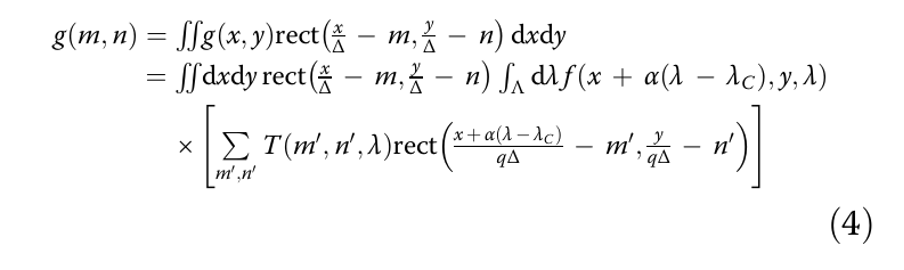
Для дальнейшего упрощения уравнения (4) мы дискретизируем функции f и T, используя интенсивность в центре пикселя.
Примем спектральное разрешение Δλ за спектральный интервал. Интенсивность f(m,n,l) (где m,n,l∈N) используется для представления пикселя спектральной плотности f(x,y,λ), при этом:
· x∈[mΔ−2Δ, mΔ+2Δ],
· y∈[nΔ−2Δ, nΔ+2Δ],
· λ∈[λC+lΔλ−2Δλ, λC+lΔλ+2Δλ].
Отрегулируем калибровочный коэффициент α так, чтобы расстояние дисперсии удовлетворяло условию αΔλ=kΔ, где k∈N.
Тогда уравнение (4) принимает вид…
Примем спектральное разрешение Δλ за спектральный интервал. Интенсивность f(m,n,l) (где m,n,l∈N) используется для представления пикселя спектральной плотности f(x,y,λ), при этом:
· x∈[mΔ−2Δ, mΔ+2Δ],
· y∈[nΔ−2Δ, nΔ+2Δ],
· λ∈[λC+lΔλ−2Δλ, λC+lΔλ+2Δλ].
Отрегулируем калибровочный коэффициент α так, чтобы расстояние дисперсии удовлетворяло условию αΔλ=kΔ, где k∈N.
Тогда уравнение (4) принимает вид…
Чтобы применить алгоритмы реконструкции, нам необходимо переписать уравнение (5) в матричной форме. Эта процедура проиллюстрирована на рис. 4.
Сначала мы векторизуем измерение и спектральный куб, как показано на рис. 4а:
Сначала мы векторизуем измерение и спектральный куб, как показано на рис. 4а:

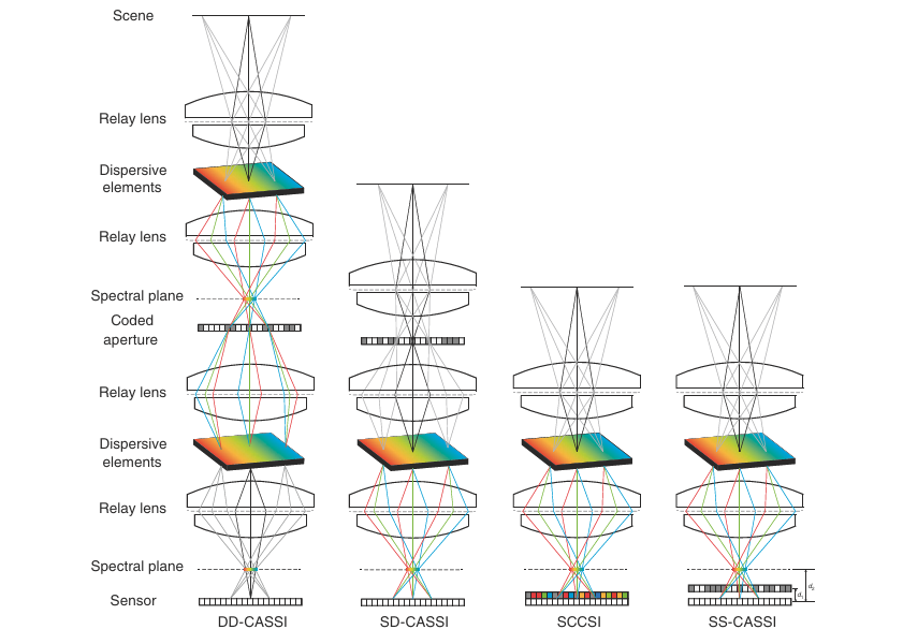
Рис. 2 Иллюстрация четырех архитектур CASSI. В архитектуре DD-CASSI спектральная сцена проходит процедуру сдвига-кодирования-обратного сдвига. В SD-CASSI перед закодированной апертурой удаляется дифракционная решетка, следовательно, процесс становится процедурой кодирования-сдвига. В SCCSI закодированная апертура расположена позади дисперсионного элемента, и спектральные данные проходят процедуру сдвига-кодирования. В SS-CASSI положение закодированной апертуры становится гибким между спектральной плоскостью и камерой сенсора, причем отношение $(d_1+d_2)/d_2$ определяет степень спектрального кодирования.
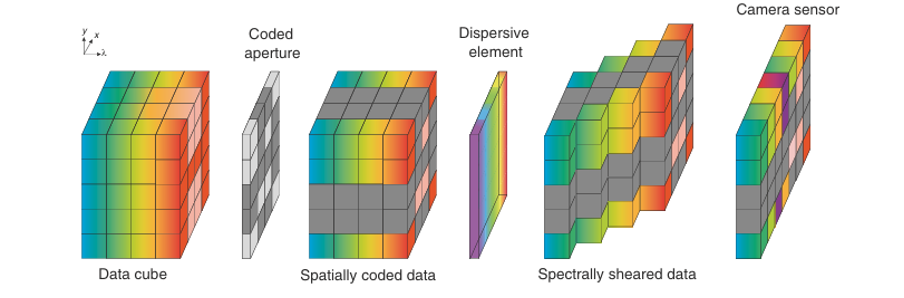
Рис. 3. Процесс спектральной визуализации в архитектуре SD‑CASSI.
Куб спектральных данных сначала проходит через кодированную апертуру, где осуществляется пространственное кодирование. Затем расположение спектральных компонент сдвигается (модулируется) с помощью дисперсионного элемента. В завершение детектор фиксирует итоговое изображение, содержащее закодированные пространственные и спектральные данные.
Куб спектральных данных сначала проходит через кодированную апертуру, где осуществляется пространственное кодирование. Затем расположение спектральных компонент сдвигается (модулируется) с помощью дисперсионного элемента. В завершение детектор фиксирует итоговое изображение, содержащее закодированные пространственные и спектральные данные.
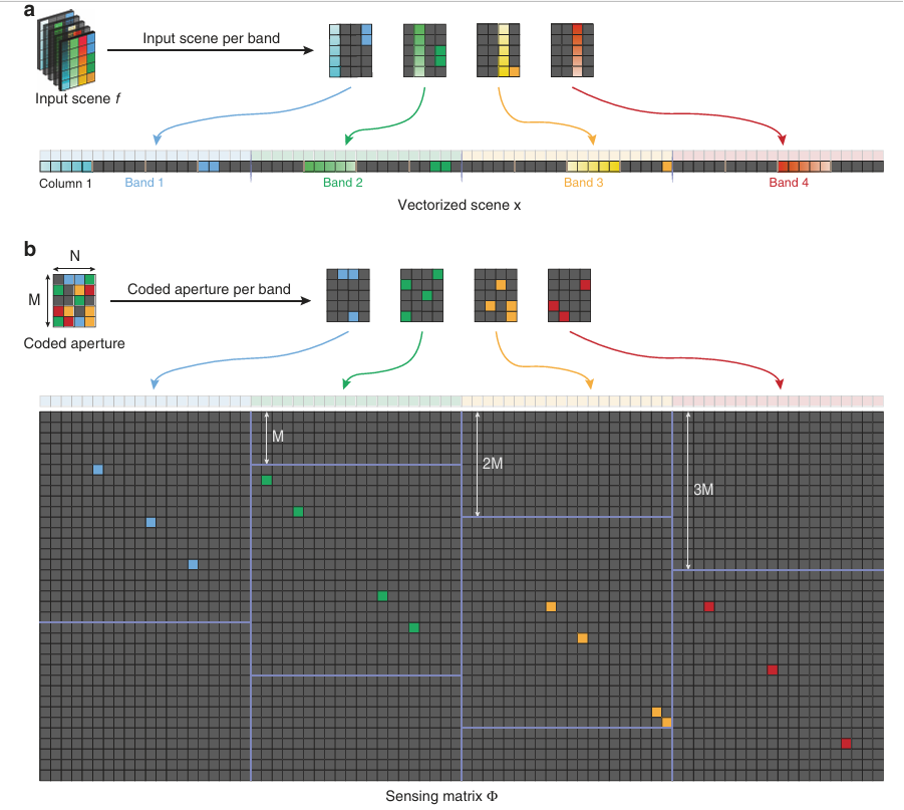
Рис. 4 Процедура векторизации и генерации матрицы измерения, связанной с закодированной апертурой.
a) Иллюстрация процесса векторизации. Для матрицы AA векторизация означает последовательное наложение столбцов AA. Для трехмерного куба спектра сцены f(m,n,l)f(m,n,l) векторизация подразумевает наложение векторизированных двумерных срезов друг на друга.
b) Иллюстрация процедуры генерации матрицы измерений из цветной закодированной апертуры в архитектуре SD-CASSI. Она состоит из набора диагональных паттернов, повторяющихся в горизонтальном направлении, каждый раз со сдвигом вниз на единицу MM, учитывающим дисперсию. Каждый диагональный паттерн генерируется из векторизированного шаблона закодированной апертуры полосы. Бинарная (черно-белая) закодированная апертура аналогична, за исключением преобразования цветовых полос в черно-белые.
где термин измерения g ∈ ℝ^M×N и спектральный куб f ∈ ℝ^M×N×L с пространственным измерением M × N и спектральным измерением L.
После векторизации мы получаем векторизованные термины: y ∈ ℝ^MN — векторизованный термин измерения; x ∈ ℝ^MNL — векторизованный спектральный куб.
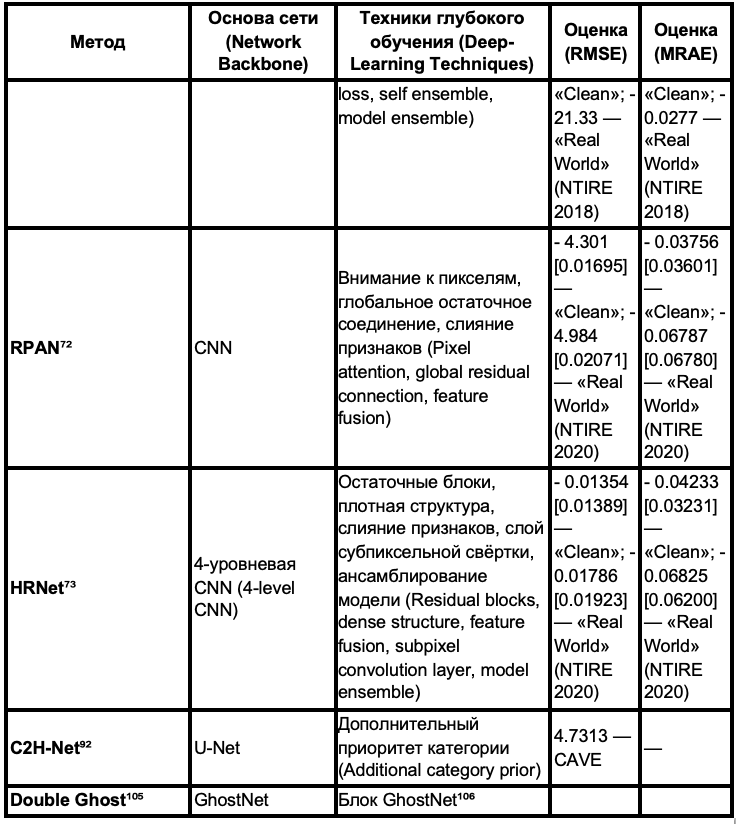
Далее кодированная апертура и сдвиг дисперсии моделируются в виде матрицы сенсинга (чувствительной матрицы) Φ ∈ ℝ^V×MNL, где: V = N + k(L – 1) — размерность, учитывающая сдвиг дисперсии; сдвиг дисперсии задаётся расстоянием αΔλ = kΔ, k ∈ ℕ (где k — натуральное число).
Матрица сенсинга (для k = 1), полученная из цветной кодированной апертуры, показана на рис. 4b.
Наконец, задача реконструкции формулируется следующим образом…
a) Иллюстрация процесса векторизации. Для матрицы AA векторизация означает последовательное наложение столбцов AA. Для трехмерного куба спектра сцены f(m,n,l)f(m,n,l) векторизация подразумевает наложение векторизированных двумерных срезов друг на друга.
b) Иллюстрация процедуры генерации матрицы измерений из цветной закодированной апертуры в архитектуре SD-CASSI. Она состоит из набора диагональных паттернов, повторяющихся в горизонтальном направлении, каждый раз со сдвигом вниз на единицу MM, учитывающим дисперсию. Каждый диагональный паттерн генерируется из векторизированного шаблона закодированной апертуры полосы. Бинарная (черно-белая) закодированная апертура аналогична, за исключением преобразования цветовых полос в черно-белые.
где термин измерения g ∈ ℝ^M×N и спектральный куб f ∈ ℝ^M×N×L с пространственным измерением M × N и спектральным измерением L.
После векторизации мы получаем векторизованные термины: y ∈ ℝ^MN — векторизованный термин измерения; x ∈ ℝ^MNL — векторизованный спектральный куб.
Далее кодированная апертура и сдвиг дисперсии моделируются в виде матрицы сенсинга (чувствительной матрицы) Φ ∈ ℝ^V×MNL, где: V = N + k(L – 1) — размерность, учитывающая сдвиг дисперсии; сдвиг дисперсии задаётся расстоянием αΔλ = kΔ, k ∈ ℕ (где k — натуральное число).
Матрица сенсинга (для k = 1), полученная из цветной кодированной апертуры, показана на рис. 4b.
Наконец, задача реконструкции формулируется следующим образом…
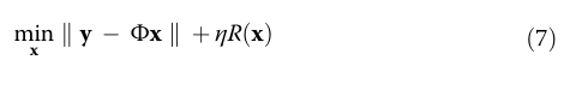
где Φ — матрица сенсинга (чувствительная матрица), а y — результат измерения (вектор измерений).
Термин R обозначает «приоритет» (regularizer) — регуляризатор, который определяется на основе априорных знаний о входной сцене x (например, её разрежённость — sparsity, то есть малое количество ненулевых элементов).
Термин η — это вес (коэффициент), который задаёт значимость (влияние) априорных знаний при решении задачи. Чем больше значение η, тем сильнее учитывается предварительная информация о сцене при реконструкции или обработке данных.
Глубокая компрессивная реконструкция
Глубокая компрессированная реконструкция
Традиционные методы реконструкции спектральных изображений обычно используют итеративные алгоритмы оптимизации, такие как GAP-TV33, ADMM34 и другие.
У этих методов есть два существенных недостатка: Длительное время реконструкции из-за необходимости выполнения множества итераций. Процесс восстановления изображения занимает много времени, так как алгоритм пошагово приближается к решению, повторяя вычисления. Невысокая точность пространственной и спектральной реконструкции при использовании «ручных» (заранее заданных) априорных предположений (priors) — то есть математических моделей, описывающих предполагаемые свойства исходного изображения.
В частности, широко применяемый в алгоритмах реконструкции критерий полной вариации (Total Variance, TV) часто приводит к избыточной сглаженности (over-smoothness) результата. Это значит, что мелкие детали изображения теряются, а границы объектов становятся размытыми — поскольку алгоритм «стремится» минимизировать резкие перепады яркости/цвета, считая их шумом.
Таким образом, традиционные методы сталкиваются с компромиссом: либо более точная, но очень медленная реконструкция с помощью итеративных методов, либо более быстрая, но менее детализированная реконструкция с использованием простых априорных моделей вроде TV.
Методы глубокого обучения можно применить на каждом этапе методов спектральной визуализации с амплитудным кодированием — от разработки стратегии амплитудного кодирования (оптимизации кодирующей апертуры) до поиска подходящего регуляризатора (термин R в уравнении (7)). При этом весь процесс реконструкции можно заменить нейронной сетью.
Использование методов глубокого обучения позволяет: Ускорить процесс реконструкции в сотни раз по сравнению с традиционными подходами. Повысить точность реконструкции как в пространственной, так и в спектральной области за счёт «обучения» априорных моделей (priors) на больших объёмах спектральных данных. Нейронные сети анализируют закономерности в данных и формируют более точные предположения о структуре исходного изображения.
В таблице 1 мы привели сравнение работ, посвящённых спектральной визуализации с кодирующей апертурой на основе глубокого обучения, которые были опубликованы за последние годы.
В зависимости от места использования глубокого обучения, мы делим методы компрессивной реконструкции на основе глубокого обучения на четыре категории:
(i) Конечная реконструкция — использует глубокие нейронные сети для прямой реконструкции;
(ii) Совместное обучение маски — одновременно обучает шаблон закодированной апертуры и последующую сеть реконструкции;
(iii) Развернутая сеть — разворачивает итеративную оптимизационную процедуру в глубокую сеть с множеством блоков этапов;
(iv) Нетренированная сеть — использует широкий диапазон нейронной сети в качестве априорного предположения и выполняет итеративную реконструкцию.
Основные идеи этих четырех категорий проиллюстрированы на рис. 5.
Таблица 1. Сравнение различных методов компрессированной спектральной визуализации с амплитудным кодированием
Термин R обозначает «приоритет» (regularizer) — регуляризатор, который определяется на основе априорных знаний о входной сцене x (например, её разрежённость — sparsity, то есть малое количество ненулевых элементов).
Термин η — это вес (коэффициент), который задаёт значимость (влияние) априорных знаний при решении задачи. Чем больше значение η, тем сильнее учитывается предварительная информация о сцене при реконструкции или обработке данных.
Глубокая компрессивная реконструкция
Глубокая компрессированная реконструкция
Традиционные методы реконструкции спектральных изображений обычно используют итеративные алгоритмы оптимизации, такие как GAP-TV33, ADMM34 и другие.
У этих методов есть два существенных недостатка: Длительное время реконструкции из-за необходимости выполнения множества итераций. Процесс восстановления изображения занимает много времени, так как алгоритм пошагово приближается к решению, повторяя вычисления. Невысокая точность пространственной и спектральной реконструкции при использовании «ручных» (заранее заданных) априорных предположений (priors) — то есть математических моделей, описывающих предполагаемые свойства исходного изображения.
В частности, широко применяемый в алгоритмах реконструкции критерий полной вариации (Total Variance, TV) часто приводит к избыточной сглаженности (over-smoothness) результата. Это значит, что мелкие детали изображения теряются, а границы объектов становятся размытыми — поскольку алгоритм «стремится» минимизировать резкие перепады яркости/цвета, считая их шумом.
Таким образом, традиционные методы сталкиваются с компромиссом: либо более точная, но очень медленная реконструкция с помощью итеративных методов, либо более быстрая, но менее детализированная реконструкция с использованием простых априорных моделей вроде TV.
Методы глубокого обучения можно применить на каждом этапе методов спектральной визуализации с амплитудным кодированием — от разработки стратегии амплитудного кодирования (оптимизации кодирующей апертуры) до поиска подходящего регуляризатора (термин R в уравнении (7)). При этом весь процесс реконструкции можно заменить нейронной сетью.
Использование методов глубокого обучения позволяет: Ускорить процесс реконструкции в сотни раз по сравнению с традиционными подходами. Повысить точность реконструкции как в пространственной, так и в спектральной области за счёт «обучения» априорных моделей (priors) на больших объёмах спектральных данных. Нейронные сети анализируют закономерности в данных и формируют более точные предположения о структуре исходного изображения.
В таблице 1 мы привели сравнение работ, посвящённых спектральной визуализации с кодирующей апертурой на основе глубокого обучения, которые были опубликованы за последние годы.
В зависимости от места использования глубокого обучения, мы делим методы компрессивной реконструкции на основе глубокого обучения на четыре категории:
(i) Конечная реконструкция — использует глубокие нейронные сети для прямой реконструкции;
(ii) Совместное обучение маски — одновременно обучает шаблон закодированной апертуры и последующую сеть реконструкции;
(iii) Развернутая сеть — разворачивает итеративную оптимизационную процедуру в глубокую сеть с множеством блоков этапов;
(iv) Нетренированная сеть — использует широкий диапазон нейронной сети в качестве априорного предположения и выполняет итеративную реконструкцию.
Основные идеи этих четырех категорий проиллюстрированы на рис. 5.
Таблица 1. Сравнение различных методов компрессированной спектральной визуализации с амплитудным кодированием
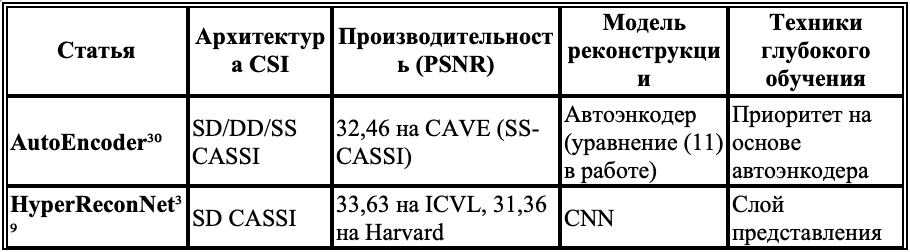
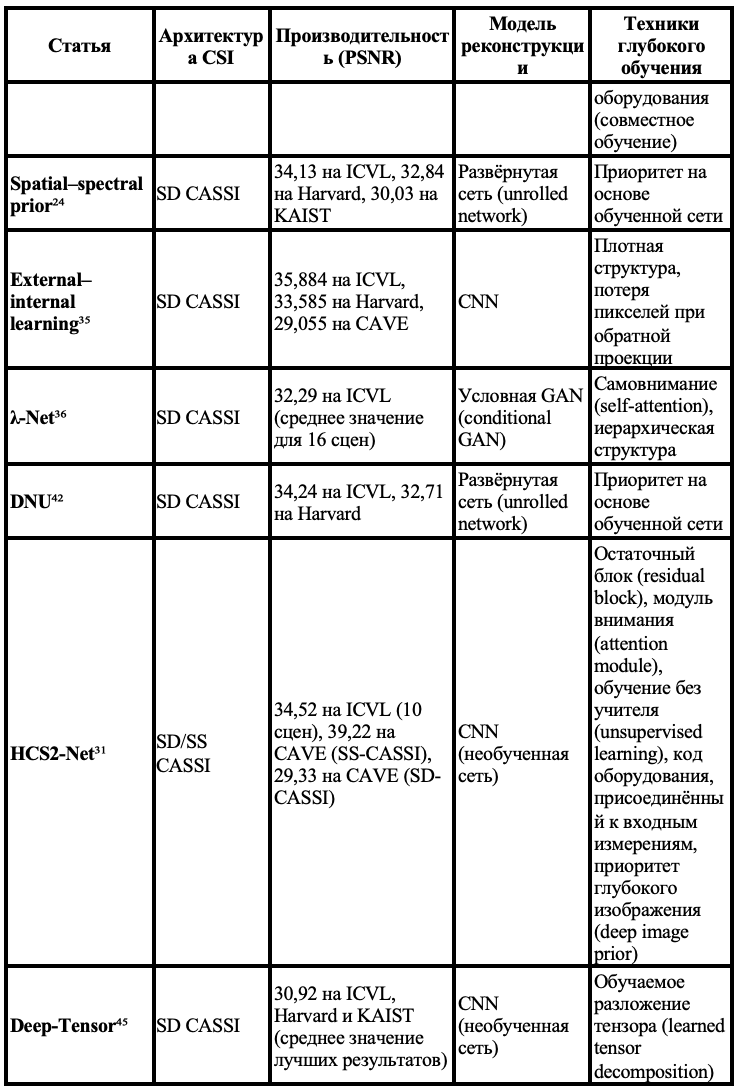
Примечание: Результаты оценки собраны из оригинальных работ.
Реконструкция «end-to-end» (E2E)
Реконструкция по принципу «end-to-end» (E2E) заключается в том, что исходные измерения передаются в глубокую нейронную сеть, которая сразу выдаёт результат реконструкции.
Среди методов E2E особый интерес представляет глубокое обучение по принципу «внешнее–внутреннее» (deep external–internal learning), в рамках которого предложена новая стратегия обучения: Внешнее обучение (external learning) на большом наборе данных — на этом этапе улучшается общая способность сети к обобщению, то есть её умение работать с разнообразными входными данными. Внутреннее обучение (internal learning) на отдельном спектральном изображении — этот этап применяется для конкретного практического случая и позволяет дополнительно повысить качество реконструкции.
Кроме того, было выявлено, что объединение (фузия) с панхроматическим изображением позволяет улучшить пространственное разрешение результата реконструкции.
Альтернативной архитектурой для E2E-реконструкции является λNet. Эта модель построена на основе условной генеративно-состязательной сети (conditional Generative Adversarial Network, cGAN). Для повышения производительности в λNet также используются: техника самовнимания (self-attention) — позволяет сети акцентировать внимание на наиболее важных частях изображения; иерархическая стратегия реконструкции (hierarchical reconstruction) — разбивает процесс реконструкции на несколько уровней, что способствует более точному восстановлению деталей изображения.
Набор данных (dataset), архитектура сети (network design) и функция потерь (loss function) — три ключевых фактора методов реконструкции «end-to-end» (E2E).
Для дальнейшего совершенствования этих методов можно использовать различные техники, применяемые при попиксельной спектральной реконструкции на основе RGB-изображений (см. раздел «RGB Pixel-wise Spectral Reconstruction»). Например, в E2E-методах целесообразно применить следующие подходы: остаточные блоки (residual blocks) — улучшают способность сети выявлять и усиливать важные детали изображения; плотная архитектура (dense structure) — увеличивает количество связей между слоями сети, повышая её выразительность и точность; модули внимания (attention module) — позволяют сети фокусироваться на наиболее значимых участках изображения, улучшая качество реконструкции.
При выборе функции потерь рекомендуется использовать потери по пикселям с обратной проекцией (back-projection pixel loss). Этот подход полезен для обеспечения достоверности данных (data fidelity) и работает следующим образом: с использованием известного паттерна кодирующей апертуры и реконструированного спектрального изображения симулируются измерения; полученные смоделированные данные (обратная проекция) сравниваются с исходным «эталоном» (ground truth).
Также можно попробовать применить новые функции потерь, такие как: потери по признакам (feature loss) — оценивают схожесть абстрактных признаков (фич) между реконструированным и исходным изображением; потери по стилю (style loss) — учитывают такие аспекты, как текстура и общее распределение цветов, помогая сохранить стилистические особенности исходного изображения.
Реконструкция «end-to-end» (E2E)
Реконструкция по принципу «end-to-end» (E2E) заключается в том, что исходные измерения передаются в глубокую нейронную сеть, которая сразу выдаёт результат реконструкции.
Среди методов E2E особый интерес представляет глубокое обучение по принципу «внешнее–внутреннее» (deep external–internal learning), в рамках которого предложена новая стратегия обучения: Внешнее обучение (external learning) на большом наборе данных — на этом этапе улучшается общая способность сети к обобщению, то есть её умение работать с разнообразными входными данными. Внутреннее обучение (internal learning) на отдельном спектральном изображении — этот этап применяется для конкретного практического случая и позволяет дополнительно повысить качество реконструкции.
Кроме того, было выявлено, что объединение (фузия) с панхроматическим изображением позволяет улучшить пространственное разрешение результата реконструкции.
Альтернативной архитектурой для E2E-реконструкции является λNet. Эта модель построена на основе условной генеративно-состязательной сети (conditional Generative Adversarial Network, cGAN). Для повышения производительности в λNet также используются: техника самовнимания (self-attention) — позволяет сети акцентировать внимание на наиболее важных частях изображения; иерархическая стратегия реконструкции (hierarchical reconstruction) — разбивает процесс реконструкции на несколько уровней, что способствует более точному восстановлению деталей изображения.
Набор данных (dataset), архитектура сети (network design) и функция потерь (loss function) — три ключевых фактора методов реконструкции «end-to-end» (E2E).
Для дальнейшего совершенствования этих методов можно использовать различные техники, применяемые при попиксельной спектральной реконструкции на основе RGB-изображений (см. раздел «RGB Pixel-wise Spectral Reconstruction»). Например, в E2E-методах целесообразно применить следующие подходы: остаточные блоки (residual blocks) — улучшают способность сети выявлять и усиливать важные детали изображения; плотная архитектура (dense structure) — увеличивает количество связей между слоями сети, повышая её выразительность и точность; модули внимания (attention module) — позволяют сети фокусироваться на наиболее значимых участках изображения, улучшая качество реконструкции.
При выборе функции потерь рекомендуется использовать потери по пикселям с обратной проекцией (back-projection pixel loss). Этот подход полезен для обеспечения достоверности данных (data fidelity) и работает следующим образом: с использованием известного паттерна кодирующей апертуры и реконструированного спектрального изображения симулируются измерения; полученные смоделированные данные (обратная проекция) сравниваются с исходным «эталоном» (ground truth).
Также можно попробовать применить новые функции потерь, такие как: потери по признакам (feature loss) — оценивают схожесть абстрактных признаков (фич) между реконструированным и исходным изображением; потери по стилю (style loss) — учитывают такие аспекты, как текстура и общее распределение цветов, помогая сохранить стилистические особенности исходного изображения.
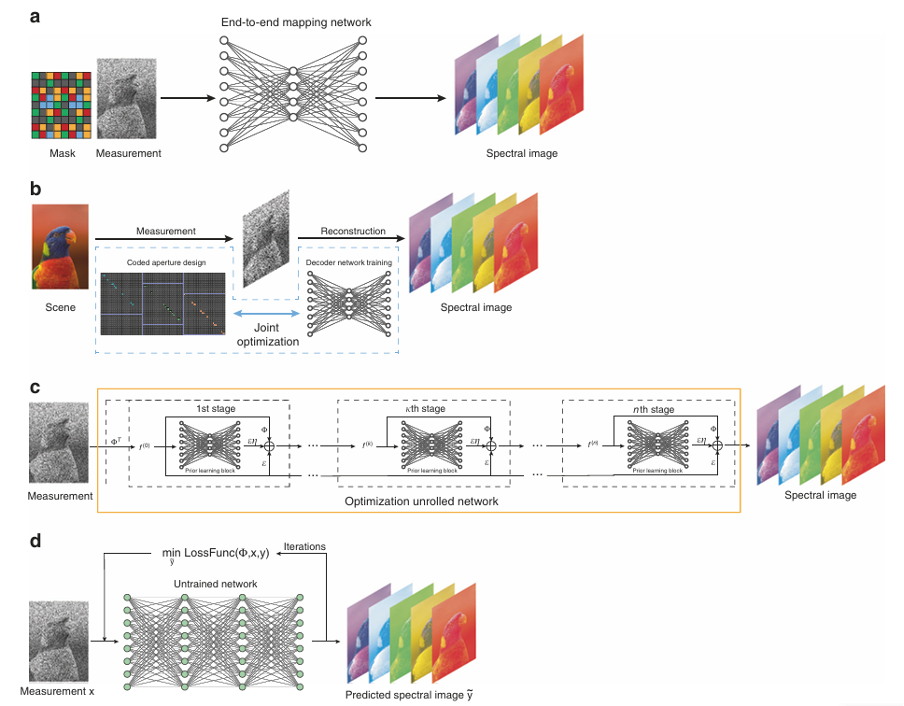
Рис. 5. Основные идеи четырёх подходов к глубокой компрессированной реконструкции.
а) End-to-end реконструкция (прямая реконструкция) б) Совместное обучение маски (joint mask learning) в) Развёрнутая сеть (unrolled network г) Необученная сеть (untrained network)
Совместное обучение маски (Joint mask learning)
Кодирующая апертура (coded aperture) связана с матрицей сенсинга (sensing matrix) Φ, которая используется в процессе получения спектральных изображений.
Традиционные методы, основанные на системе CASSI (Compressed APS with Spectral Imaging), обычно используют случайные кодирующие апертуры. Причина этого — случайный код с высокой вероятностью сохраняет свойства, необходимые для реконструкции изображения, например, свойство ограниченной изометрии (Restricted Isometry Property, RIP).
Как показано в работе, существуют подходы к оптимизации кодирующих апертур с использованием RIP в качестве критерия. Однако такая оптимизация не даёт существенного улучшения по сравнению со случайными масками.
В архитектуре глубокой компрессированной реконструкции кодирующая апертура рассматривается как энкодер— элемент, который встраивает спектральные характеристики сигнала. Следовательно, её необходимо оптимизировать совместно с декодером, то есть с сетью реконструкции.
HyperReconNet реализует совместный процесс обучения: кодирующей апертуры; свёрточной нейронной сети (CNN) для реконструкции изображения.
В этой архитектуре: Кодирующая апертура добавляется в сеть как отдельный слой. Для преобразования числовых (float) значений в бинарные элементы кодирующей апертуры применяется метод BinaryConnect.
Однако большинство работ, использующих глубокое обучение, не уделяли должного внимания оптимизации кодирующей апертуры. Поэтому это направление требует более глубоких исследований.
Развёрнутая сеть (Unrolled network)
Развёрнутая сеть преобразует итеративный процесс оптимизации (используемый для реконструкции изображения) в структуру нейронной сети.
Принцип работы: каждый блок развёрнутой сети «обучается» решать задачу одной итерации в алгоритме оптимизации; вместо пошагового выполнения итераций алгоритм «разворачивается» в последовательность слоёв нейронной сети.
Ключевые исследования:
1. Сеть с априорными данными для гиперспектральных изображений (Wang et al., 2024): разработана на основе задачи итеративной реконструкции; использует метод half-quadratic splitting (HQS) для получения формулы итеративной оптимизации; процесс реконструкции, состоящий из K итераций, преобразован в нейронную сеть с K этапами (каждая стадия соответствует одной итерации).
2. Deep Non-local Unrolling (DNU): упрощает формулу, предложенную в работе; преобразует последовательную структуру сети (из работы) в параллельную, что ускоряет вычисления.
3. Сеть, вдохновлённая алгоритмом ADMM (Sogabe et al.): предназначена для компрессированного спектрального imaging; разворачивает процесс адаптивного ADMM в многоступенчатую нейронную сеть; демонстрирует улучшение производительности по сравнению с методом, основанным на HQS.
Преимущества развёрнутых сетей: ускорение реконструкции — параметры итераций «замораживаются» в слоях нейронной сети, что исключает необходимость повторных вычислений; объяснимость модели — каждый этап сети решает конкретное уравнение итерации, что делает работу сети прозрачной и понятной.
Необученная сеть (Untrained network)
Концепция глубокого априорного образа (deep image prior), предложенная в работе [44], утверждает: структура генеративной сети сама по себе достаточна для учёта априорных знаний об изображении при реконструкции.
Суть подхода: диапазон возможных представлений глубокой нейронной сети достаточно широк, чтобы охватить все типичные спектральные изображения, подлежащие восстановлению; следовательно, тщательно спроектированная необученная (т. е. не прошедшая предварительного обучения на размеченных данных) сеть способна выполнять реконструкцию спектральных изображений.
Преимущества метода: отсутствие необходимости в предварительном обучении — не требуется набор размеченных данных для тренировки; высокая обобщающая способность — сеть адаптируется к конкретному входному сигналу в процессе итеративной оптимизации; гибкость — архитектура сети служит априорной моделью структуры изображения.
Недостатки: требует итеративной процедуры градиентного спуска, что может быть вычислительно затратным.
Примеры реализации
1. HCS2‑Net [31]:
o на вход сети подаются:
§ случайный код кодирующей апертуры;
§ снимок измерения (snapshot measurement);
o используется обучение без учителя (unsupervised network learning) для спектральной реконструкции;
o для повышения возможностей сети применены современные техники глубокого обучения:
§ остаточные блоки (residual block);
§ модули внимания (attention module).
2. Метод на основе тензорной декомпозиции [45]:
o спектральный куб данных рассматривается как 3D‑тензор;
o выполняется обучаемая декомпозиция Таккера (learned Tucker decomposition) [46];
o слои сети спроектированы на основе декомпозиции Таккера;
o используется априорное предположение о низком ранге (low rank prior) ядра тензора, что помогает лучше уловить структуру спектральных данных.
Примечание. В таблице 1 методы, отмеченные как untrained, используют именно этот подход к компрессированной спектральной реконструкции.
. В таблице 1 методы, отмеченные как untrained, используют именно этот подход к компрессированной спектральной реконструкции. HCS2-Net [31] принимал случайный код закодированной апертуры и мгновенное измерение в качестве входных данных сети и использовал обучение сети без учителя для спектральной реконструкции. Они применяли множество методов глубокого обучения, таких как остаточные блоки и модули внимания, для повышения возможностей сети. В [45] спектральный куб данных рассматривался как 3D-тензор, и выполняется обучаемая декомпозиция Таккера (learned Tucker decomposition) [46]. Они разработали слои сети на основе декомпозиции Тукера и используется априорное предположение о низком ранге (low rank prior) ядра тензора, что помогает лучше уловить структуру спектральных данных.
Фазовое кодирование спектрального изображения
Фазовое кодирование спектрального изображения формулирует процесс генерации изображения как процесс свертки между функцией рассеяния точки (PSF), специфичной для длины волны, и монохромным изображением объекта на каждой длине волны. Фазовое кодирование манипулирует фазовым членом PSF, что позволяет различать спектральные сигнатуры при распространении света. По сравнению с амплитудным кодированием спектрального изображения, фазовый подход может значительно увеличить пропускную способность света (а следовательно, и отношение сигнал/шум). Поскольку фазовое кодирование в основном осуществляется на тонком дифракционном оптическом элементе (DOE), который легко прикрепить к камере, система фазового кодирования спектрального изображения может быть очень компактной.
Спектральную сигнатуру можно восстановить, разработав алгоритмы с соответствующим DOE (также называемым дифракционным элементом в некоторых работах [16,47–49]). С помощью глубокого обучения эти методы показали сопоставимую производительность. Кроме того, благодаря зависимости от глубины модели дифракции, они также могут получать информацию о глубине, помимо спектральной сигнатуры сцены [50].
Фазовый подход к спектральному изображению состоит из двух частей:
(i) стратегия фазового кодирования, часто связанная с проектированием DOE;
(ii) разработка алгоритма реконструкции.
В этом разделе мы сначала опишем модель дифракции фазового кодирования, а затем представим работы, использующие различные стратегии фазового кодирования и системы, основанные на глубоком обучении.
Дифракционная модель
Система фазового кодирования спектрального изображения основана на предыдущих работах по дифракционному изображению [51,52]. Система часто состоит из дифракционного оптического элемента (DOE) (прозрачного или отражающего) и голого датчика камеры, разделенных расстоянием z. Как показано на рис. 6, существуют два типа систем фазового кодирования спектрального изображения: система DOE-Френель дифракции (слева) и система DOE-Линза (справа), в зависимости от наличия линзы.
Построение PSF
Мы используем прозрачный DOE для вывода модели. PSF pλ(x,y)pλ(x,y) — это системный отклик на точечный источник в плоскости изображения. Предположим, что падающее волновое поле в точке (x0,y0)(x0,y0) координат DOE на длине волны λλ равно...
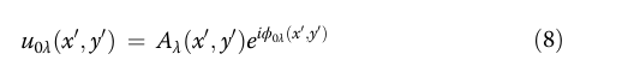
Волновое поле сначала претерпевает фазовый сдвиг ϕh, определяемый профилем высоты ДОЭ (дифракционного оптического элемента).
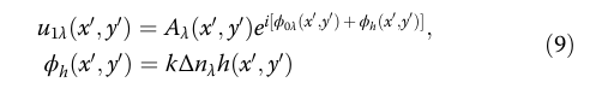
де Δn — разность показателей преломления между ДОЭ (n(λ)) и воздухом;
k = 2π/λ — волновое число (λ — длина волны).
Для системы DOE‑lens функция рассеяния точки (PSF) имеет вид [16]:
k = 2π/λ — волновое число (λ — длина волны).
Для системы DOE‑lens функция рассеяния точки (PSF) имеет вид [16]:
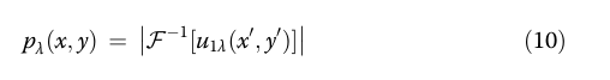
где F−1 — обратное двумерное преобразование Фурье, обусловленное фурье‑свойствами линзы.
Для системы DOE‑Fresnel diffraction распространение волнового поля на расстояние z описывается законом дифракции Френеля при условии, что λ≪z.
Для системы DOE‑Fresnel diffraction распространение волнового поля на расстояние z описывается законом дифракции Френеля при условии, что λ≪z.
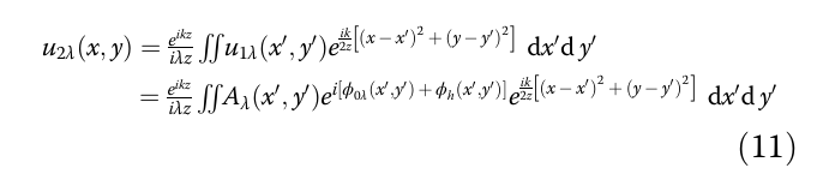
Наконец, для удобства вычислений мы раскладываем уравнение (11) и представляем его с помощью преобразования Фурье ℱ. Итоговая функция рассеяния точки (PSF) формулируется как…
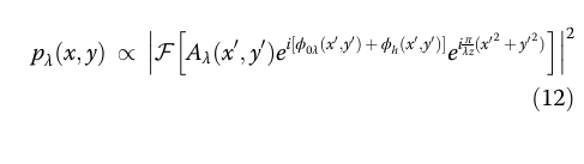
Формирование изображения
Рассматривая распределение объекта oλ(x0,y0) на плоскости ДОЭ (дифракционного оптического элемента), мы можем разложить его на интеграл по точкам объекта:
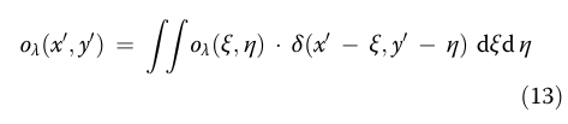
Перед попаданием на сенсор спектральное распределение…
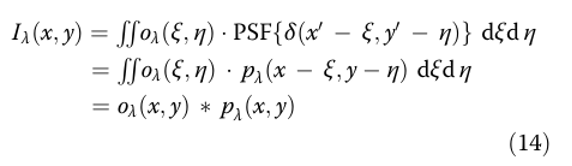
где PSF обозначает отклик системы на точечный источник, а pλ сдвигается на величины ξ и η по осям x и y — вследствие аналогичного сдвига самого точечного источника.
Наконец, на плоскости сенсора (с учётом спектральной чувствительности сенсора D) интенсивность определяется как…
Наконец, на плоскости сенсора (с учётом спектральной чувствительности сенсора D) интенсивность определяется как…
Аналогично рис. 4, векторизуем oλoλ в xx и матрицу свертки с функцией PSF в ΦΦ, мы можем дискретизировать уравнение (15) и сформулировать задачу реконструкции как уравнение (7). Исследователи могут использовать аналогичные оптимизационные алгоритмы или инструменты глубокого обучения для проектирования DOE и восстановления спектрального изображения.
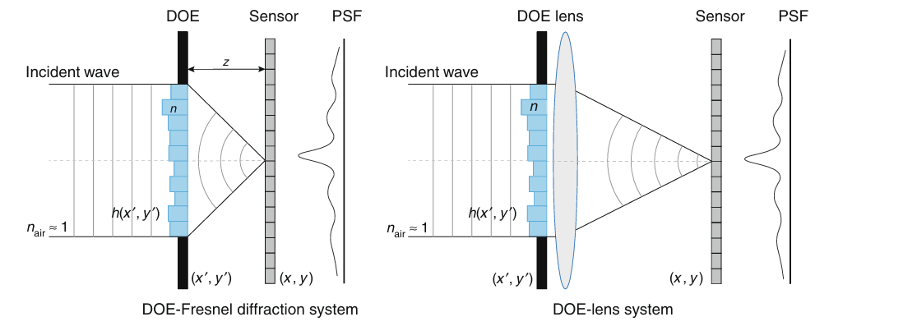
Рис. 6 Схематическое изображение дифракционного спектрального изображения с использованием дифракционного оптического элемента (DOE).Слева показана система, использующая прозрачный DOE и датчик, где падающая волна проходит через DOE, а затем распространяется на расстояние zz перед попаданием на датчик. Распространение можно смоделировать с помощью дифракции Френеля. Справа система использует изображение линзы непосредственно за DOE. После прохождения через DOE падающая волна фокусируется на датчике через линзу. DOE имеет профиль высоты, который вводит фазовый сдвиг.
Стратегии фазового кодирования
Хорошо продуманная конструкция PSF (функции рассеяния точки) способствует эффективному фазовому кодированию, что позволяет получить более точные результаты спектральной реконструкции. Учитывая незначительные различия в системах формирования изображения, мы классифицируем ниже представленные стратегии фазового кодирования.
DOE с дифракцией Френеля
Многие методы фазового кодирования спектрального изображения разработаны на основе дифракционного вычислительного цветного изображения. Пэн и др. [53] предложили оптимизационный подход к проектированию DOE для получения формы инвариантной PSF по отношению к длине волны. Вместе с методом деconvolution они реконструировали высококачественное цветное изображение.
Хотя форма инвариантной PSF [53] полезна для высококачественного ахроматического изображения, наложение PSF на каждой длине волны вызывает трудности при спектральной реконструкции, что ограничивает его применение в спектральном изображении. Джон и др. [15] разработали спектрально изменяющуюся PSF, которая регулярно вращается с длиной волны, что кодирует спектральную информацию. Их конструкция вращающейся PSF делает ее отличной на разных длинах волн, что очень подходит для спектрального изображения. Поместив результирующее изображение интенсивности в оптимизационную развернутую сеть, они достигли высокого отношения пик-сигнал-шум (PSNR) и спектральной точности в видимом диапазоне длин волн, в очень компактной системе.
DOE/рассеиватель с линзой
Аналогичная архитектура использует DOE (или рассеиватель) с расположенной непосредственно за ним линзой для формирования изображения, что показано на рис. 6 (справа). В 2016 году Голуб и соавторы [49] предложили простую оптическую систему «рассеиватель‑линза» и применили алгоритм, основанный на сжатом зондировании, для спектральной реконструкции.
Хаузер и соавторы [16] расширили эту работу, перейдя к двумерному бинарному рассеивателю (для бинарного фазового кодирования) и использовав глубокую нейронную сеть (названную DD‑Net) для спектральной реконструкции. Они сообщили о высококачественной реконструкции как в ходе моделирования, так и в лабораторных экспериментах.
Сочетание с другими методами кодирования
Сочетание фазового кодирования с другими архитектурами кодирования также является осуществимым подходом, причём глубокое обучение способно работать с такими сложными комбинированными архитектурными моделями.
Например, метод компрессионной дифракционной спектральной визуализации объединяет DOE для фазового кодирования с кодированными апертурами для дополнительного амплитудного кодирования [54]. Однако процесс реконструкции весьма сложен, а световая эффективность невысока.
Другой пример — сочетание с массивом оптических фильтров. Опираясь на предыдущие работы по беслинзовой визуализации [47, 55], Монахова и соавторы предложили спектральную систему DiffuserCam [48]. В ней используется рассеиватель для распределения точечного источника и плиточный массив фильтров для дополнительного кодирования по длине волны.
Поскольку этот метод имеет схожую математическую модель формирования спектра, перспективно применение глубокого обучения для решения сложной задачи реконструкции в спектральной системе DiffuserCam.
Спектральная съёмка с кодированием по длине волны
Спектральная съёмка с кодированием по длине волны использует оптические фильтры для кодирования спектральной сигнатуры вдоль оси длин волн.
Среди методов кодирования по длине волны чаще всего применяется RGB‑изображение, которое кодируется с помощью узкополосных RGB‑фильтров. Необходимо восстанавливать спектральное изображение из RGB‑изображения, поскольку: RGB‑изображение широко используется людьми в повседневной практике; соответствующее спектральное изображение является основой для отображения сцен на мониторах.
На протяжении многих лет исследователи ищут быстрые и точные методы спектральной съёмки с кодированием по длине волны. Они обнаружили, что RGB‑фильтры могут быть неоптимальными, поэтому изучают: различные узкополосные фильтры; специально разработанные широкополосные фильтры.
Модель формирования изображения
Сначала рассмотрим модель формирования изображения в контексте кодирования по длине волны.
Пусть Ik(x,y) — интенсивность, регистрируемая пикселем в точке (x,y), где k — индекс канала, указывающий на различную модуляцию по длине волны.
Для RGB‑изображения k∈{1,2,3}, что соответствует красному, зелёному и синему каналам.
Закодированная интенсивность формируется на основе спектров отражения сцены S при освещении E:
Стратегии фазового кодирования
Хорошо продуманная конструкция PSF (функции рассеяния точки) способствует эффективному фазовому кодированию, что позволяет получить более точные результаты спектральной реконструкции. Учитывая незначительные различия в системах формирования изображения, мы классифицируем ниже представленные стратегии фазового кодирования.
DOE с дифракцией Френеля
Многие методы фазового кодирования спектрального изображения разработаны на основе дифракционного вычислительного цветного изображения. Пэн и др. [53] предложили оптимизационный подход к проектированию DOE для получения формы инвариантной PSF по отношению к длине волны. Вместе с методом деconvolution они реконструировали высококачественное цветное изображение.
Хотя форма инвариантной PSF [53] полезна для высококачественного ахроматического изображения, наложение PSF на каждой длине волны вызывает трудности при спектральной реконструкции, что ограничивает его применение в спектральном изображении. Джон и др. [15] разработали спектрально изменяющуюся PSF, которая регулярно вращается с длиной волны, что кодирует спектральную информацию. Их конструкция вращающейся PSF делает ее отличной на разных длинах волн, что очень подходит для спектрального изображения. Поместив результирующее изображение интенсивности в оптимизационную развернутую сеть, они достигли высокого отношения пик-сигнал-шум (PSNR) и спектральной точности в видимом диапазоне длин волн, в очень компактной системе.
DOE/рассеиватель с линзой
Аналогичная архитектура использует DOE (или рассеиватель) с расположенной непосредственно за ним линзой для формирования изображения, что показано на рис. 6 (справа). В 2016 году Голуб и соавторы [49] предложили простую оптическую систему «рассеиватель‑линза» и применили алгоритм, основанный на сжатом зондировании, для спектральной реконструкции.
Хаузер и соавторы [16] расширили эту работу, перейдя к двумерному бинарному рассеивателю (для бинарного фазового кодирования) и использовав глубокую нейронную сеть (названную DD‑Net) для спектральной реконструкции. Они сообщили о высококачественной реконструкции как в ходе моделирования, так и в лабораторных экспериментах.
Сочетание с другими методами кодирования
Сочетание фазового кодирования с другими архитектурами кодирования также является осуществимым подходом, причём глубокое обучение способно работать с такими сложными комбинированными архитектурными моделями.
Например, метод компрессионной дифракционной спектральной визуализации объединяет DOE для фазового кодирования с кодированными апертурами для дополнительного амплитудного кодирования [54]. Однако процесс реконструкции весьма сложен, а световая эффективность невысока.
Другой пример — сочетание с массивом оптических фильтров. Опираясь на предыдущие работы по беслинзовой визуализации [47, 55], Монахова и соавторы предложили спектральную систему DiffuserCam [48]. В ней используется рассеиватель для распределения точечного источника и плиточный массив фильтров для дополнительного кодирования по длине волны.
Поскольку этот метод имеет схожую математическую модель формирования спектра, перспективно применение глубокого обучения для решения сложной задачи реконструкции в спектральной системе DiffuserCam.
Спектральная съёмка с кодированием по длине волны
Спектральная съёмка с кодированием по длине волны использует оптические фильтры для кодирования спектральной сигнатуры вдоль оси длин волн.
Среди методов кодирования по длине волны чаще всего применяется RGB‑изображение, которое кодируется с помощью узкополосных RGB‑фильтров. Необходимо восстанавливать спектральное изображение из RGB‑изображения, поскольку: RGB‑изображение широко используется людьми в повседневной практике; соответствующее спектральное изображение является основой для отображения сцен на мониторах.
На протяжении многих лет исследователи ищут быстрые и точные методы спектральной съёмки с кодированием по длине волны. Они обнаружили, что RGB‑фильтры могут быть неоптимальными, поэтому изучают: различные узкополосные фильтры; специально разработанные широкополосные фильтры.
Модель формирования изображения
Сначала рассмотрим модель формирования изображения в контексте кодирования по длине волны.
Пусть Ik(x,y) — интенсивность, регистрируемая пикселем в точке (x,y), где k — индекс канала, указывающий на различную модуляцию по длине волны.
Для RGB‑изображения k∈{1,2,3}, что соответствует красному, зелёному и синему каналам.
Закодированная интенсивность формируется на основе спектров отражения сцены S при освещении E:
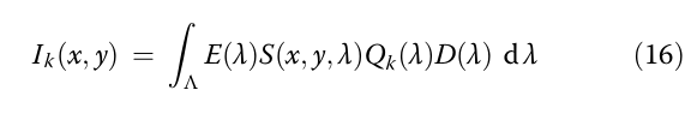
где Qk — кривая пропускания k-го фильтра, D — чувствительность камеры, а Λ — диапазон длин волн.
Распределение освещённости E и спектральное отражение сцены S можно объединить в спектральную яркость сцены R:
Распределение освещённости E и спектральное отражение сцены S можно объединить в спектральную яркость сцены R:
Процесс формирования изображения показан на рис. 7.
На практике у нас имеются закодированные интенсивности объекта I и кривые пропускания фильтров Q, однако чувствительность камеры D порой неудобно измерять. Поэтому во многих методах её принимают идеально равномерной.
В экспериментальных условиях нам также известна освещённость E.
После дискретизации уравнение (17) (или уравнение (16)) превращается в задачу обращения матрицы, которая является недоопределённой (т. е. число неизвестных превышает число уравнений).
Попиксельная спектральная реконструкция по RGB
Ранние работы по спектральной реконструкции с кодированием по длине волны выполнялись попиксельно на RGB‑изображениях. В них рассматривалась упрощённая задача: как восстановить векторный спектр с большим числом каналов из трёхканального RGB‑вектора — без учёта характеристик отклика RGB‑фильтров конкретной камеры.
В целом попиксельные методы стремятся: найти способ представления отдельного спектра (либо через вложение в многообразие, либо через базисные функции); разработать методы реконструкции спектра на основе этого представления.
Существует два основных подхода к представлению спектра:
1. Обучение многообразия спектра (spectrum manifold learning) — поиск скрытого пространства вложения многообразия, позволяющего эффективно выражать спектр.
2. Аппроксимация базисными функциями (basis function fitting) — разложение спектра по набору базисных функций и подбор небольшого числа коэффициентов.
Обучение многообразия спектра
Этот подход исходит из предположения, что спектр y определяется вектором x в низкоразмерном многообразии M. Задача состоит в том, чтобы найти отображение f, связывающее y с x:
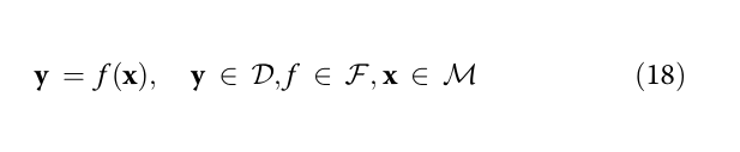
где D — высокоразмерное пространство данных (обычно M ⊂ Rm, D ⊂ Rn, причём m,n ∈ N — размерности пространств);
F — функциональное пространство, содержащее функции, отображающие данные из M в D.
Обучение многообразия предполагает, что низкоразмерное многообразие M вложено в высокоразмерное пространство данных D, и ставит задачу восстановить M по данным, заданным в D.
В работе [56] предложен трёхэтапный метод:
Сеть на радиальных базисных функциях и метод обучения словаря можно заменить глубокими нейронными сетями (например, автоэнкодером, AutoEncoder) для повышения качества реконструкции. Таким образом, реконструкция на основе многообразия может быть существенно улучшена.
F — функциональное пространство, содержащее функции, отображающие данные из M в D.
Обучение многообразия предполагает, что низкоразмерное многообразие M вложено в высокоразмерное пространство данных D, и ставит задачу восстановить M по данным, заданным в D.
В работе [56] предложен трёхэтапный метод:
- Определить подходящую размерность пространства многообразия с помощью изометрического отображения признаков (Isometric Feature Mapping, Isomap [57]).
- Обучить сеть на радиальных базисных функциях (Radial Basis Function, RBF) для вложения RGB‑вектора в M. Этим определяется обратное отображение f−1 в уравнении (18).
- Использовать обучение словаря (dictionary learning), чтобы отобразить представление на многообразии в M обратно в спектральное пространство. Этим определяется функция f в уравнении (18).
Сеть на радиальных базисных функциях и метод обучения словаря можно заменить глубокими нейронными сетями (например, автоэнкодером, AutoEncoder) для повышения качества реконструкции. Таким образом, реконструкция на основе многообразия может быть существенно улучшена.
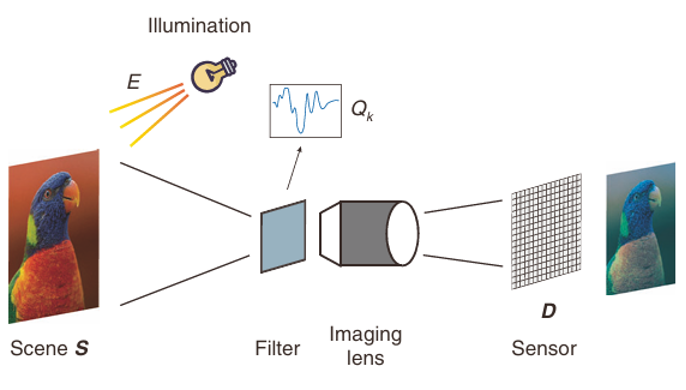
Рис. 7. Иллюстрация процесса спектральной съёмки с кодированием по длине волны.
Сцена S освещается источником света E и кодируется по длине волны с помощью фильтров Q. Затем закодированная спектральная яркость сцены регистрируется объективом на сенсоре со спектральной чувствительностью D.
Подход с подбором базисных функций
Этот подход исходит из предположения, что спектр y=y(λ) раскладывается по набору базисных функций {ϕ1(λ),…,ϕN(λ)}:
Сцена S освещается источником света E и кодируется по длине волны с помощью фильтров Q. Затем закодированная спектральная яркость сцены регистрируется объективом на сенсоре со спектральной чувствительностью D.
Подход с подбором базисных функций
Этот подход исходит из предположения, что спектр y=y(λ) раскладывается по набору базисных функций {ϕ1(λ),…,ϕN(λ)}:

где α — коэффициенты, подлежащие подбору (определению).
В краткой заметке Гласснера [17] был разработан простой метод обращения матрицы для преобразования RGB в спектр. Однако полученный спектр содержит лишь три ненулевые компоненты, что редко встречается в реальных условиях.
В конце заметки автор предложил подход с взвешенным подбором базисных функций для построения спектра из RGB‑триплета — с использованием трёх функций: константы, синуса и косинуса.
Для моделирования интерференции света Сун и соавторы [18] сравнили различные базисные функции для вывода спектров из цветов и предложили адаптивный метод с применением гауссовых функций.
Нгуен и соавторы [20] развили подход с базисными функциями, предложив метод, основанный на данных: он обучает сеть на радиальных базисных функциях (RBF) для преобразования нормализованного по освещённости RGB‑изображения в спектральное.
В работе [21] с помощью алгоритма K‑SVD был построен избыточный гиперспектральный словарь на основе предложенного набора данных. Словарь содержит набор почти ортогональных векторов, которые можно рассматривать как обученные базисные функции.
Аналогично подходу с обучением словаря, для изучения базисных функций можно применять инструменты глубокого обучения.
В работе [58] базисные функции формируются в процессе обучения, а коэффициенты предсказываются с помощью U‑Net на этапе тестирования. Этот метод весьма эффективен с точки зрения вычислений, поскольку на этапе тестирования требуется подобрать лишь небольшое число коэффициентов.
Хотя точность спектральной реконструкции в этом случае не столь высока, как у других методов на основе свёрточных нейронных сетей (CNN), которые эффективно извлекают корреляции между спектральными фрагментами, данный подход оказался самым быстрым в конкурсе NTIRE 2020: время реконструкции составило всего 34 мс на изображение.
Пофрагментная спектральная реконструкция по RGB
Как отмечено в работе [22], спектры в пределах фрагмента изображения обладают определённой корреляцией. Однако попиксельные методы не способны использовать эту корреляцию, что может приводить к более низкой точности реконструкции по сравнению с пофрагментными подходами.
В работе [59] предложен ручной способ извлечения признаков фрагмента посредством операции свёртки. Он позволяет выделить окрестные признаки RGB‑пикселя на основе обучающего спектрального набора данных. Эта работа дала практическое представление о том, как использовать такие признаки фрагмента в спектральном изображении — что идеально подходит для свёрточных нейронных сетей (CNN).
Свёрточные нейронные сети способны выполнять более сложное выделение признаков за счёт множества операций свёртки.
· В 2017 году Сюн и соавторы предложили HSCNN [23] — метод, применяющий CNN к увеличенным по разрешению RGB‑изображениям и амплитудно‑кодированным измерениям для спектральной реконструкции.
· В том же году Гальяни и соавторы разработали метод обученной спектральной суперразрешающей реконструкции [60], используя CNN для сквозной реконструкции спектрального изображения из RGB.
Эти работы продемонстрировали высокую точность спектральной реконструкции на многих открытых спектральных наборах данных, стимулировав дальнейшие исследования в области спектральной реконструкции на основе CNN.
Число подобных работ стремительно выросло после проведения конкурсов New Trends in Image Restoration and Enhancement (NTIRE) в 2018 году [61] и 2020 году [25]. В них приняли участие многочисленные группы, занимающиеся глубоким обучением, и внесли вклад в исследование различных сетевых архитектур для спектральной реконструкции.
Методы на основе нейронных сетей используют преимущества глубокого обучения и лучше улавливают корреляцию между спектрами фрагментов. В разных работах применяются:
· разнообразные архитектуры сетей;
· передовые методы глубокого обучения.
Эти подходы систематизированы в таблице 2.
Таблица 2. Сравнение работ на основе нейронных сетей для сквозной спектральной реконструкции из RGB-изображений
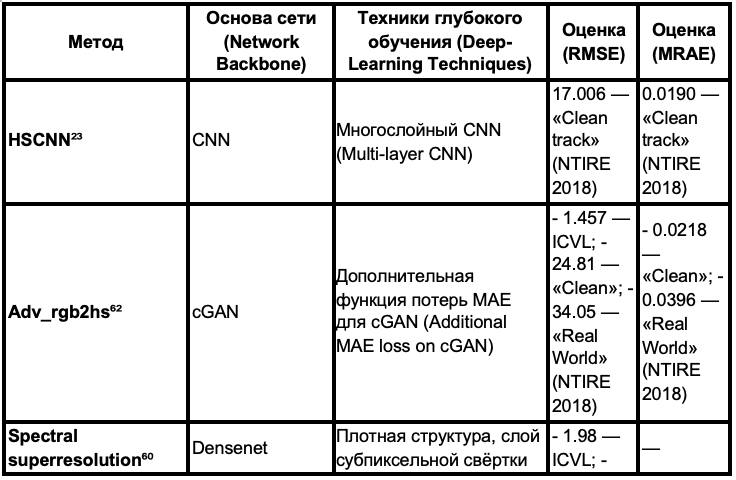
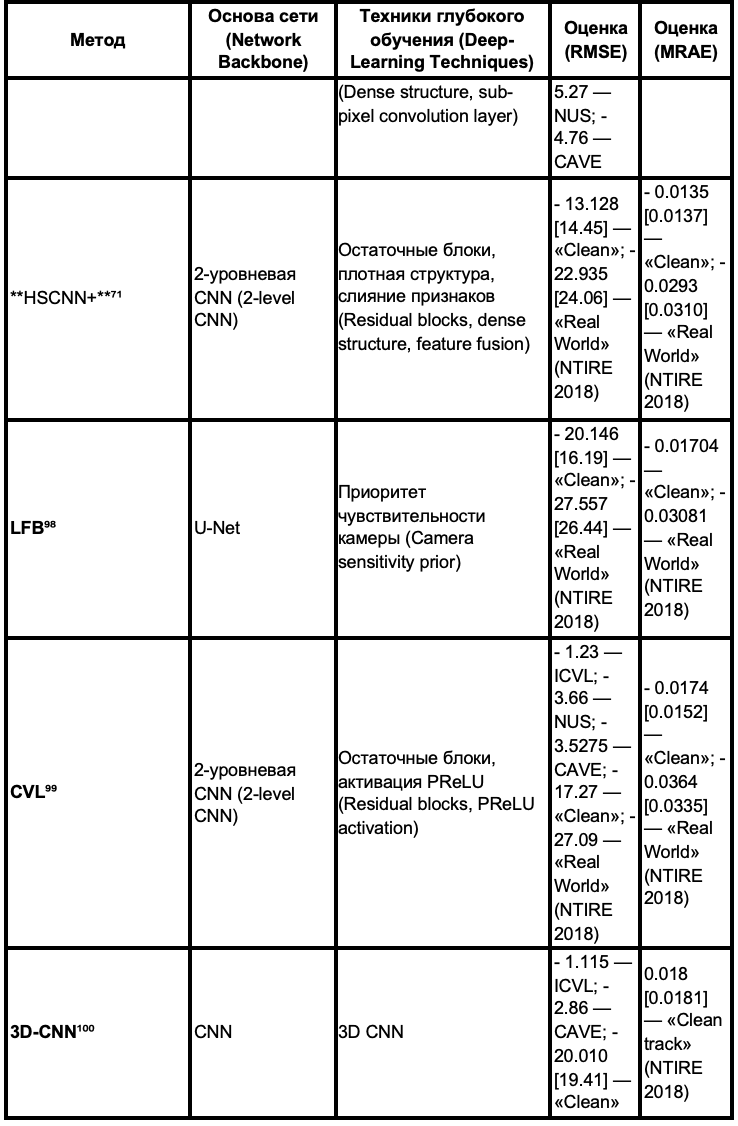
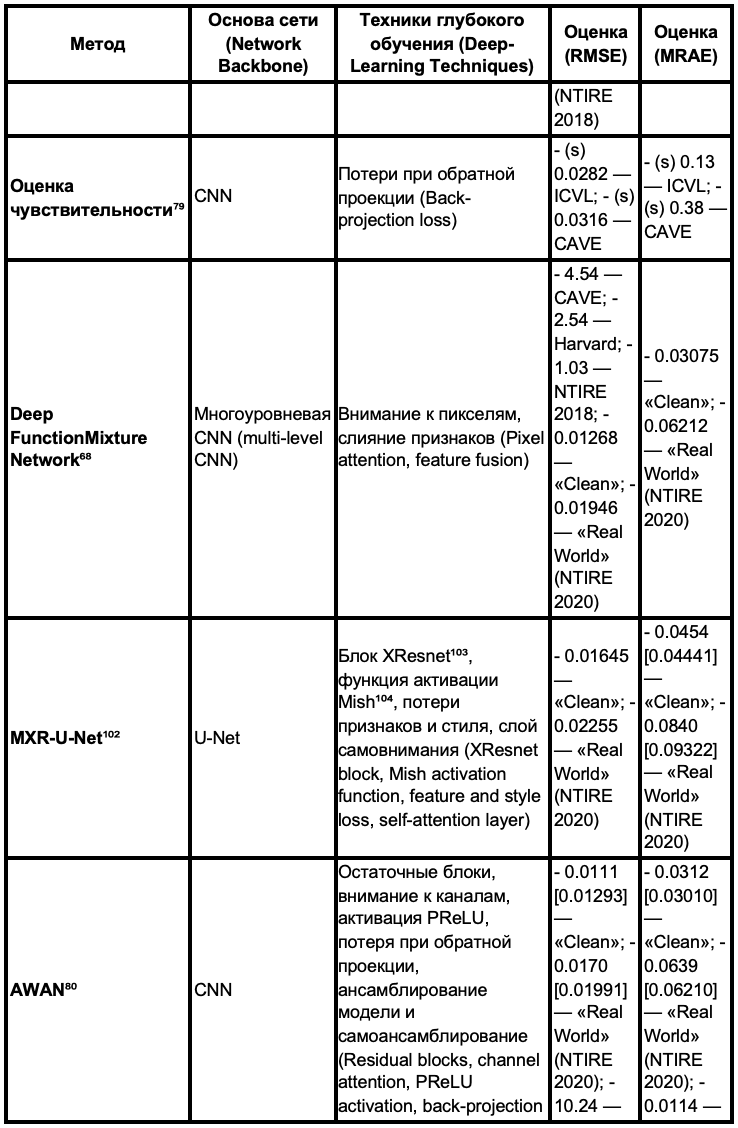
В колонке сетевой архитектуры, уровень означает параллельные слои CNN для потока данных. В колонке техники глубокого обучения мы выделяем техники, которые могут играть важную роль в производительности метода. Оценки производительности взяты из результатов оригинальных статей или отчета NTIRE. Оценочные результаты из масштабированных наборов данных (наборы данных, которые линейно масштабированы в диапазоне [0,1]) помечены звездочкой "*".
Используя передовые методы глубокого обучения
Мы можем почерпнуть некоторые идеи из таблицы 2. Во‑первых, большинство работ основано на свёрточных нейронных сетях (CNN), вероятно, потому, что CNN лучше извлекают спектральную информацию из фрагментов изображения, чем генеративно‑состязательные сети (GAN). Существует работа, основанная на условной GAN (cGAN) [62], которая использует RGB‑изображение в качестве условного входного сигнала. В ней также применялась функция потерь на основе L₁‑расстояния (средняя абсолютная ошибка, согласно [63]), чтобы уменьшить размытие, однако точность реконструкции оказалась ниже, чем у HSCNN [23]: в работе [62] относительное среднеквадратичное отклонение (RMSE) на наборе данных ICVL составило 0,0401, тогда как у HSCNN — 0,0388.
Кроме того, внедряются и демонстрируют эффективность многие передовые методы глубокого обучения. Например, всё чаще используются остаточные блоки [64] и плотная структура [65]. Это связано с тем, что остаточные соединения позволяют расширить поле восприятия сети, а плотная структура улучшает процесс передачи признаков, что приводит к более эффективному извлечению корреляций между спектральными фрагментами.
Механизм внимания [66] — популярный метод глубокого обучения, который также применяется в работах по спектральной съёмке. Для спектральной реконструкции существуют два вида внимания:
Модуль внимания обучается определять пространственные или спектральные веса, помогая сети фокусироваться на информативных частях спектрального изображения.
Слияние признаков — это объединение нескольких параллельных слоёв, которое исследовалось в работе [70]. Этот метод применялся в работах [71–73] и показал положительное влияние на спектральную реконструкцию.
Наконец, для дальнейшего повышения производительности сети рекомендуется использовать метод ансамблей. Существуют два вида стратегий ансамблей: ансамблевое обучение моделей и самоансамблирование.
Одиночная сеть может попасть в локальный минимум, что приводит к ухудшению обобщающей способности. Применяя метод ансамблей, можно объединить знания нескольких сетей или разные точки зрения на один и тот же входной сигнал.
Сеть HRNet [73] использовала ансамблевое обучение моделей, и это позволило улучшить результаты реконструкции.
Поскольку спектральная реконструкция представляет собой задачу типа «изображение‑в‑изображение», многие работы заимствуют эффективные методы глубокого обучения из других задач такого же типа, например:
· архитектуру U‑Net [74] — из задачи сегментации;
· слой субпиксельной свёртки [75];
· механизм внимания по каналам [69] — из задачи сверхразрешения изображений;
· функцию потерь по признакам (feature loss) и функцию потерь по стилю (style loss) — из задачи переноса стиля изображения [76, 77].
Это также является способом внедрения передовых методов глубокого обучения в задачу спектральной реконструкции.
Инвариантность освещения
Спектр отражения объекта без учёта освещения — желаемая цель для спектральной реконструкции, поскольку он объективно отражает компоненты и свойства сцены. Чтобы восстановить спектр отражения объекта, необходимо исключить освещение среды E из спектральной яркости сцены R. Однако измерить спектры освещения зачастую затруднительно.
Исследователи часто используют свойство инвариантности спектра объекта относительно освещения, чтобы отделить привнесённое освещение от спектральной яркости сцены.
В работе [20] предложен подход, использующий инвариантность относительно освещения. Авторы предложили выполнять балансировку белого по RGB‑каналам, чтобы нормализовать освещение сцены. В качестве дополнительного результата они могут оценить освещение среды, сравнивая реконструированную сцену с исходной.
В работе [78] для получения устойчивого спектра из зашумлённого входного сигнала использовался шумоподавляющий автоэнкодер (Denoising AutoEncoder, DAE). Входное данные содержали исходный спектр при различных условиях освещения. Благодаря такому преобразованию «многое‑в‑одно» реконструкция спектра стала инвариантной относительно освещения.
Использование отклика RGB-фильтра
Отклик RGB-фильтра является функцией кодирования длины волны Q в уравнении (16). Во многих работах [79,80] отклик RGB-фильтра называется априорной информацией о спектральной чувствительности камеры (CSS). Чтобы избежать семантической двусмысленности CSS и отклика камеры D в уравнении (16), мы заменяем его на отклик RGB-фильтра.
Отклик RGB-фильтра не всегда доступен для практических приложений, что является заметной проблемой. Общим способом решения этой проблемы является использование функции цветового отображения CIE для симуляции [81]. В работе [79] было предложено другое решение этой проблемы. Они использовали классификационную нейронную сеть для оценки подходящего отклика RGB-фильтра из заданного набора чувствительности камеры. Затем они могли использовать оцененную функцию отклика фильтра и другую сеть для восстановления спектральной сигнатуры. Эти две сети были обучены вместе с помощью единой функции потерь.
Когда отклик RGB-фильтра известен, RGB-изображение может быть реконструировано из спектрального изображения, поэтому может быть использован метод обратного проецирования (или перцептивная) потеря. Эксперименты показали преимущества добавления априорной информации о фильтре отклика в процессе реконструкции. Например, AWAN [80], занявший 1-е место в NTIRE 2020 на чистом треке, использовал кривые отклика фильтра в функции потерь и получил небольшое улучшение по метрике MRAE.
В работе [82] отклик RGB-фильтра Q был тщательно изучен. Они продемонстрировали, что реконструированный спектр должен удовлетворять свойству цветопередачи QTψ(I) = I, где ψ - это отображение RGB в спектр, а I - интенсивность пикселя RGB.
Они определили множество спектров, которые удовлетворяют свойству цветопередачи, как допустимое множество:
Используя передовые методы глубокого обучения
Мы можем почерпнуть некоторые идеи из таблицы 2. Во‑первых, большинство работ основано на свёрточных нейронных сетях (CNN), вероятно, потому, что CNN лучше извлекают спектральную информацию из фрагментов изображения, чем генеративно‑состязательные сети (GAN). Существует работа, основанная на условной GAN (cGAN) [62], которая использует RGB‑изображение в качестве условного входного сигнала. В ней также применялась функция потерь на основе L₁‑расстояния (средняя абсолютная ошибка, согласно [63]), чтобы уменьшить размытие, однако точность реконструкции оказалась ниже, чем у HSCNN [23]: в работе [62] относительное среднеквадратичное отклонение (RMSE) на наборе данных ICVL составило 0,0401, тогда как у HSCNN — 0,0388.
Кроме того, внедряются и демонстрируют эффективность многие передовые методы глубокого обучения. Например, всё чаще используются остаточные блоки [64] и плотная структура [65]. Это связано с тем, что остаточные соединения позволяют расширить поле восприятия сети, а плотная структура улучшает процесс передачи признаков, что приводит к более эффективному извлечению корреляций между спектральными фрагментами.
Механизм внимания [66] — популярный метод глубокого обучения, который также применяется в работах по спектральной съёмке. Для спектральной реконструкции существуют два вида внимания:
- пространственное внимание (например, слой самовнимания [67, 68]);
- спектральное внимание (внимание по каналам [69]).
Модуль внимания обучается определять пространственные или спектральные веса, помогая сети фокусироваться на информативных частях спектрального изображения.
Слияние признаков — это объединение нескольких параллельных слоёв, которое исследовалось в работе [70]. Этот метод применялся в работах [71–73] и показал положительное влияние на спектральную реконструкцию.
Наконец, для дальнейшего повышения производительности сети рекомендуется использовать метод ансамблей. Существуют два вида стратегий ансамблей: ансамблевое обучение моделей и самоансамблирование.
- Ансамблевое обучение моделей усредняет результаты сетей, переобученных с разными параметрами.
- Самоансамблирование усредняет результаты обработки преобразованного входного сигнала одной и той же сетью.
Одиночная сеть может попасть в локальный минимум, что приводит к ухудшению обобщающей способности. Применяя метод ансамблей, можно объединить знания нескольких сетей или разные точки зрения на один и тот же входной сигнал.
Сеть HRNet [73] использовала ансамблевое обучение моделей, и это позволило улучшить результаты реконструкции.
Поскольку спектральная реконструкция представляет собой задачу типа «изображение‑в‑изображение», многие работы заимствуют эффективные методы глубокого обучения из других задач такого же типа, например:
· архитектуру U‑Net [74] — из задачи сегментации;
· слой субпиксельной свёртки [75];
· механизм внимания по каналам [69] — из задачи сверхразрешения изображений;
· функцию потерь по признакам (feature loss) и функцию потерь по стилю (style loss) — из задачи переноса стиля изображения [76, 77].
Это также является способом внедрения передовых методов глубокого обучения в задачу спектральной реконструкции.
Инвариантность освещения
Спектр отражения объекта без учёта освещения — желаемая цель для спектральной реконструкции, поскольку он объективно отражает компоненты и свойства сцены. Чтобы восстановить спектр отражения объекта, необходимо исключить освещение среды E из спектральной яркости сцены R. Однако измерить спектры освещения зачастую затруднительно.
Исследователи часто используют свойство инвариантности спектра объекта относительно освещения, чтобы отделить привнесённое освещение от спектральной яркости сцены.
В работе [20] предложен подход, использующий инвариантность относительно освещения. Авторы предложили выполнять балансировку белого по RGB‑каналам, чтобы нормализовать освещение сцены. В качестве дополнительного результата они могут оценить освещение среды, сравнивая реконструированную сцену с исходной.
В работе [78] для получения устойчивого спектра из зашумлённого входного сигнала использовался шумоподавляющий автоэнкодер (Denoising AutoEncoder, DAE). Входное данные содержали исходный спектр при различных условиях освещения. Благодаря такому преобразованию «многое‑в‑одно» реконструкция спектра стала инвариантной относительно освещения.
Использование отклика RGB-фильтра
Отклик RGB-фильтра является функцией кодирования длины волны Q в уравнении (16). Во многих работах [79,80] отклик RGB-фильтра называется априорной информацией о спектральной чувствительности камеры (CSS). Чтобы избежать семантической двусмысленности CSS и отклика камеры D в уравнении (16), мы заменяем его на отклик RGB-фильтра.
Отклик RGB-фильтра не всегда доступен для практических приложений, что является заметной проблемой. Общим способом решения этой проблемы является использование функции цветового отображения CIE для симуляции [81]. В работе [79] было предложено другое решение этой проблемы. Они использовали классификационную нейронную сеть для оценки подходящего отклика RGB-фильтра из заданного набора чувствительности камеры. Затем они могли использовать оцененную функцию отклика фильтра и другую сеть для восстановления спектральной сигнатуры. Эти две сети были обучены вместе с помощью единой функции потерь.
Когда отклик RGB-фильтра известен, RGB-изображение может быть реконструировано из спектрального изображения, поэтому может быть использован метод обратного проецирования (или перцептивная) потеря. Эксперименты показали преимущества добавления априорной информации о фильтре отклика в процессе реконструкции. Например, AWAN [80], занявший 1-е место в NTIRE 2020 на чистом треке, использовал кривые отклика фильтра в функции потерь и получил небольшое улучшение по метрике MRAE.
В работе [82] отклик RGB-фильтра Q был тщательно изучен. Они продемонстрировали, что реконструированный спектр должен удовлетворять свойству цветопередачи QTψ(I) = I, где ψ - это отображение RGB в спектр, а I - интенсивность пикселя RGB.
Они определили множество спектров, которые удовлетворяют свойству цветопередачи, как допустимое множество:
где r - спектр. Концепция физически допустимого была проиллюстрирована на рисунке 8.
Они предполагают, что реконструированный спектр должен содержать две части: одну из пространства, охватываемого тремя столбцовыми векторами отклика фильтра в Q, и другую из ортогонального дополнения к этому пространству. Формально, существует ортогональный базис B ∈ Rn-3 такой, что BTQ=0. Следовательно, спектр, подлежащий реконструкции, может быть расширен как
Они предполагают, что реконструированный спектр должен содержать две части: одну из пространства, охватываемого тремя столбцовыми векторами отклика фильтра в Q, и другую из ортогонального дополнения к этому пространству. Формально, существует ортогональный базис B ∈ Rn-3 такой, что BTQ=0. Следовательно, спектр, подлежащий реконструкции, может быть расширен как

где PQ и PB — операторы проекции.
Обратите внимание: PQ можно точно вычислить заранее, что сокращает размерность задачи реконструкции на 3.
Оставшаяся задача — оценить векторный спектр в ортогональном пространстве векторов отклика фильтров. Это можно сделать путём обучения глубокой нейронной сети.
За пределами RGB-фильтров
Поскольку RGB-изображение содержит ограниченную информацию, исследователи склонны вручную добавлять больше информации перед реконструкцией. Существует два способа реализации этого:
(i) использование самостоятельно разработанного широкополосного кодирования длины волны для расширения диапазона модуляции; (ii) увеличение количества кодирующих фильтров. Работы в этой области в основном используют инструменты глубокого обучения для проектирования кривых отклика фильтров и выполнения спектральной реконструкции [83-85], поскольку проектирование модуляции и процесс реконструкции являются сложными в вычислениях.
Обратите внимание: PQ можно точно вычислить заранее, что сокращает размерность задачи реконструкции на 3.
Оставшаяся задача — оценить векторный спектр в ортогональном пространстве векторов отклика фильтров. Это можно сделать путём обучения глубокой нейронной сети.
За пределами RGB-фильтров
Поскольку RGB-изображение содержит ограниченную информацию, исследователи склонны вручную добавлять больше информации перед реконструкцией. Существует два способа реализации этого:
(i) использование самостоятельно разработанного широкополосного кодирования длины волны для расширения диапазона модуляции; (ii) увеличение количества кодирующих фильтров. Работы в этой области в основном используют инструменты глубокого обучения для проектирования кривых отклика фильтров и выполнения спектральной реконструкции [83-85], поскольку проектирование модуляции и процесс реконструкции являются сложными в вычислениях.
Рис. 8. Иллюстрация физически неправдоподобного и правдоподобного множеств.
Физически неправдоподобное множество (слева) — это точки спектра, которые не могут быть отображены в исходную RGB‑точку с помощью отклика RGB‑фильтра.
Физически правдоподобное множество (справа) — это точки спектра, которые могут быть отображены обратно в исходную RGB‑точку посредством того же отклика RGB‑фильтра.
Физически неправдоподобное множество (слева) — это точки спектра, которые не могут быть отображены в исходную RGB‑точку с помощью отклика RGB‑фильтра.
Физически правдоподобное множество (справа) — это точки спектра, которые могут быть отображены обратно в исходную RGB‑точку посредством того же отклика RGB‑фильтра.
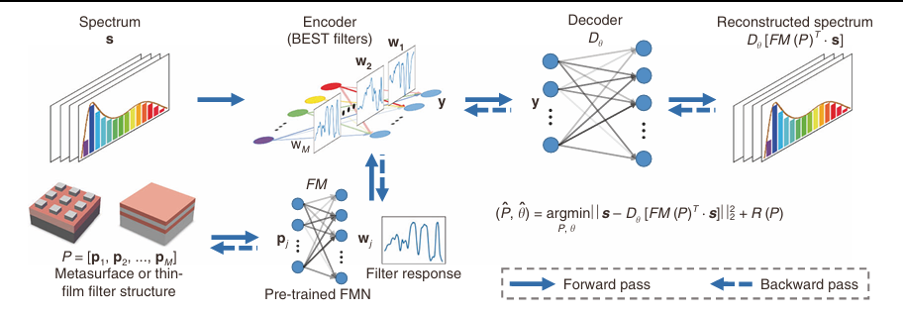
Рис. 9. Схема фреймворка PCSED. Широкополосные стохастические фильтры кодирования (BEST) действуют как кодирующая нейронная сеть (энкодер), где изученные веса представляют собой отклики фильтров. Веса ограничены параметрами структуры фильтров и генерируются с помощью предварительно обученной сети прямого моделирования структуры в отклики (FMN). Рисунок перепечатан из работы по лицензии Creative Commons Attribution 4.0 International (CC BY).
Используя широкополосные фильтры
Исходя из идеи о том, что спектральная характеристика отклика традиционной RGB‑камеры неоптимальна для реконструкции спектра, Nie и соавторы [83] применили свёрточные нейронные сети (CNN) для разработки функций отклика фильтров и совместной реконструкции спектрального изображения.
Они отметили сходство между массивом фильтров камеры и ядрами свёрточного слоя (мозаика фильтра Байера аналогична свёрточному ядру размером 2×2) и использовали фильтры камеры как аппаратный слой реализации нейронной сети.
Результаты их работы продемонстрировали улучшение по сравнению с традиционными методами, основанными на RGB‑фильтрах. Однако из‑за ограничений технологии производства фильтров они рассматривали только коммерчески доступные фильтры.
С развитием современных технологий производства фильтров стало возможным создавать гибкие фильтры с заданными спектральными характеристиками. Song и соавторы представили совместную обучающую структуру для проектирования широкополосных фильтров, названную «спектральный кодировщик и декодировщик с параметрическими ограничениями» (PCSED) [84], как показано на рис. 9.
Они совместно обучали кривые отклика фильтров (в качестве спектрального кодировщика) и сеть декодера для реконструкции спектра. Благодаря развитию индустрии производства тонкоплёночных фильтров они смогли разрабатывать разнообразные функции отклика фильтров, оптимальные для декодера.
Авторы расширили свою работу в источнике [85] и получили впечатляющие результаты. Разработанное аппаратное обеспечение — камера с широкополосным кодированием и стохастической выборкой (BEST) — продемонстрировало значительные улучшения по следующим параметрам:
· устойчивость к шуму;
· скорость реконструкции;
· спектральное разрешение (301 канал).
В качестве перспективного направления на будущее можно выделить антишумовые оптические фильтры, производимые на основе метаповерхностей, — их развитие становится возможным благодаря прогрессу в теории и промышленности метаповерхностей [86].
Увеличение числа фильтров
Увеличение числа фильтров — это прямой способ повысить точность реконструкции, поскольку при этом предоставляется больше кодирующей информации. Однако это неизбежно приводит к увеличению объёма системы.
Альтернативный способ осуществления модуляции по длине волны — использование жидких кристаллов (ЖК). В этом случае изменение напряжения переключает ЖК в другой режим модуляции. Таким образом, удобно применять множество модуляций, подавая различные напряжения.
Благодаря быстрому изменению напряжения на ЖК можно получить несколько операторов кодирования по длине волны — это эквивалентно увеличению числа фильтров.
Архитектура компрессионного миниатюрного ультраспектрального имиджера (CS‑MUSI) способна модулировать спектр подобно множеству оптических фильтров — это возможно благодаря различной реакции фазового замедлителя на жидких кристаллах на разные длины волн.
Оикни и соавторы рассмотрели реконструкцию спектра с помощью прибора CS‑MUSI в источнике [87]. Они также предложили DeepCubeNet [88], в котором: использовалась система CS‑MUSI для выполнения 32 различных модуляций по длине волны; применялась свёрточная нейронная сеть (CNN) для реконструкции спектрального изображения.
Спектральные наборы данных для визуализации
Спектральные наборы данных, содержащие реалистичные пары «спектральное изображение – RGB‑изображение», имеют большое значение для методов спектральной визуализации, основанных на данных, — особенно для тех, что используют глубокое обучение.
Наиболее часто для обучения и оценки в исследованиях по реконструкции спектра применяются следующие наборы данных: CAVE [89]; NUS [20]; ICVL [21];тKAIST [30].
Также доступны и другие наборы данных, в том числе: Harvard [22]; Hyperspectral & Color Imaging [90]; Scyllarus hyperspectral dataset [91]; C2H [92].
Для стимулирования исследований по реконструкции спектра из RGB‑изображений в 2018 и 2 Newton 2020 годах были проведены соревнования. В рамках этих мероприятий предоставили: расширенный набор данных ICVL (NTIRE 2018 [61]); крупнейшую на тот момент базу данных NTIRE 2020 [25].
Мы суммируем общедоступные наборы данных спектральных изображений в приведённых ниже таблицах. Таблица 3 даёт общий обзор спектральных наборов данных. Таблица 4 содержит подробное описание данных.
Для этих наборов данных по‑прежнему существуют две проблемы:
1. Недостаточная ёмкость для извлечения пространственно‑спектральных признаков высокой сложности.
2. Отсутствие фиксированного разделения на обучающую и тестовую выборки.
Некоторые наборы данных не предусматривают фиксированного разделения на обучающую и тестовую выборки. Это приводит к некорректному сравнению методов, в которых используются разные стратегии такого разделения.
Поэтому важно иметь крупную стандартизированную базу данных. Мы рассчитываем, что такая база будет обладать беспрецедентным масштабом, точностью и разнообразием — это позволит активизировать будущие исследования.
На текущем этапе, когда столь масштабный стандартизированный набор данных ещё не доступен, мы полагаем, что популярные наборы данных — ICVL [21], CAVE [89], NUS [20] и KAIST [30] — вполне достаточны для анализа точности реконструкции как в пространственной, так и в спектральной области.
Метрики качества спектральных изображений
Существует множество метрик, используемых для оценки производительности в спектральной реконструкции, и мы ссылаемся на работу [93] для их определения и сравнения.
В общем, PSNR, индекс структурного сходства (SSIM) и карта спектральных углов (SAM) в основном используются для методов кодирования амплитуды, в то время как различные метрики, такие как среднеквадратическая ошибка (RMSE) и средняя относительная абсолютная ошибка (MRAE), применяются для методов кодирования длины волны. В результате, неудобно сравнивать производительность между методами кодирования длины волны и методами кодирования амплитуды. Поэтому, для удобства сообщества при сравнении различных методов, необходимо установить единые метрики. Мы считаем, что некоторые общие метрики необходимы для сравнения между двумя методами. Например, SSIM, RMSE и RMAE могут быть использованы обоими методами для оценки.
Кроме того, нам также нужны метрики для сравнения скорости реконструкции. Различные работы выполняют спектральную реконструкцию для изображений с различным разрешением на различных вычислительных устройствах. Мы считаем, что скорость реконструкции пикселей является надежной метрикой для сравнения скорости реконструкции. Это средняя скорость на тестовом наборе данных, деленная на 3D-разрешение данных (т.е. общее количество пикселей спектральных данных, используемых для тестирования).
Таблица 3. Параметры спектрального набора данных
Используя широкополосные фильтры
Исходя из идеи о том, что спектральная характеристика отклика традиционной RGB‑камеры неоптимальна для реконструкции спектра, Nie и соавторы [83] применили свёрточные нейронные сети (CNN) для разработки функций отклика фильтров и совместной реконструкции спектрального изображения.
Они отметили сходство между массивом фильтров камеры и ядрами свёрточного слоя (мозаика фильтра Байера аналогична свёрточному ядру размером 2×2) и использовали фильтры камеры как аппаратный слой реализации нейронной сети.
Результаты их работы продемонстрировали улучшение по сравнению с традиционными методами, основанными на RGB‑фильтрах. Однако из‑за ограничений технологии производства фильтров они рассматривали только коммерчески доступные фильтры.
С развитием современных технологий производства фильтров стало возможным создавать гибкие фильтры с заданными спектральными характеристиками. Song и соавторы представили совместную обучающую структуру для проектирования широкополосных фильтров, названную «спектральный кодировщик и декодировщик с параметрическими ограничениями» (PCSED) [84], как показано на рис. 9.
Они совместно обучали кривые отклика фильтров (в качестве спектрального кодировщика) и сеть декодера для реконструкции спектра. Благодаря развитию индустрии производства тонкоплёночных фильтров они смогли разрабатывать разнообразные функции отклика фильтров, оптимальные для декодера.
Авторы расширили свою работу в источнике [85] и получили впечатляющие результаты. Разработанное аппаратное обеспечение — камера с широкополосным кодированием и стохастической выборкой (BEST) — продемонстрировало значительные улучшения по следующим параметрам:
· устойчивость к шуму;
· скорость реконструкции;
· спектральное разрешение (301 канал).
В качестве перспективного направления на будущее можно выделить антишумовые оптические фильтры, производимые на основе метаповерхностей, — их развитие становится возможным благодаря прогрессу в теории и промышленности метаповерхностей [86].
Увеличение числа фильтров
Увеличение числа фильтров — это прямой способ повысить точность реконструкции, поскольку при этом предоставляется больше кодирующей информации. Однако это неизбежно приводит к увеличению объёма системы.
Альтернативный способ осуществления модуляции по длине волны — использование жидких кристаллов (ЖК). В этом случае изменение напряжения переключает ЖК в другой режим модуляции. Таким образом, удобно применять множество модуляций, подавая различные напряжения.
Благодаря быстрому изменению напряжения на ЖК можно получить несколько операторов кодирования по длине волны — это эквивалентно увеличению числа фильтров.
Архитектура компрессионного миниатюрного ультраспектрального имиджера (CS‑MUSI) способна модулировать спектр подобно множеству оптических фильтров — это возможно благодаря различной реакции фазового замедлителя на жидких кристаллах на разные длины волн.
Оикни и соавторы рассмотрели реконструкцию спектра с помощью прибора CS‑MUSI в источнике [87]. Они также предложили DeepCubeNet [88], в котором: использовалась система CS‑MUSI для выполнения 32 различных модуляций по длине волны; применялась свёрточная нейронная сеть (CNN) для реконструкции спектрального изображения.
Спектральные наборы данных для визуализации
Спектральные наборы данных, содержащие реалистичные пары «спектральное изображение – RGB‑изображение», имеют большое значение для методов спектральной визуализации, основанных на данных, — особенно для тех, что используют глубокое обучение.
Наиболее часто для обучения и оценки в исследованиях по реконструкции спектра применяются следующие наборы данных: CAVE [89]; NUS [20]; ICVL [21];тKAIST [30].
Также доступны и другие наборы данных, в том числе: Harvard [22]; Hyperspectral & Color Imaging [90]; Scyllarus hyperspectral dataset [91]; C2H [92].
Для стимулирования исследований по реконструкции спектра из RGB‑изображений в 2018 и 2 Newton 2020 годах были проведены соревнования. В рамках этих мероприятий предоставили: расширенный набор данных ICVL (NTIRE 2018 [61]); крупнейшую на тот момент базу данных NTIRE 2020 [25].
Мы суммируем общедоступные наборы данных спектральных изображений в приведённых ниже таблицах. Таблица 3 даёт общий обзор спектральных наборов данных. Таблица 4 содержит подробное описание данных.
Для этих наборов данных по‑прежнему существуют две проблемы:
1. Недостаточная ёмкость для извлечения пространственно‑спектральных признаков высокой сложности.
2. Отсутствие фиксированного разделения на обучающую и тестовую выборки.
Некоторые наборы данных не предусматривают фиксированного разделения на обучающую и тестовую выборки. Это приводит к некорректному сравнению методов, в которых используются разные стратегии такого разделения.
Поэтому важно иметь крупную стандартизированную базу данных. Мы рассчитываем, что такая база будет обладать беспрецедентным масштабом, точностью и разнообразием — это позволит активизировать будущие исследования.
На текущем этапе, когда столь масштабный стандартизированный набор данных ещё не доступен, мы полагаем, что популярные наборы данных — ICVL [21], CAVE [89], NUS [20] и KAIST [30] — вполне достаточны для анализа точности реконструкции как в пространственной, так и в спектральной области.
Метрики качества спектральных изображений
Существует множество метрик, используемых для оценки производительности в спектральной реконструкции, и мы ссылаемся на работу [93] для их определения и сравнения.
В общем, PSNR, индекс структурного сходства (SSIM) и карта спектральных углов (SAM) в основном используются для методов кодирования амплитуды, в то время как различные метрики, такие как среднеквадратическая ошибка (RMSE) и средняя относительная абсолютная ошибка (MRAE), применяются для методов кодирования длины волны. В результате, неудобно сравнивать производительность между методами кодирования длины волны и методами кодирования амплитуды. Поэтому, для удобства сообщества при сравнении различных методов, необходимо установить единые метрики. Мы считаем, что некоторые общие метрики необходимы для сравнения между двумя методами. Например, SSIM, RMSE и RMAE могут быть использованы обоими методами для оценки.
Кроме того, нам также нужны метрики для сравнения скорости реконструкции. Различные работы выполняют спектральную реконструкцию для изображений с различным разрешением на различных вычислительных устройствах. Мы считаем, что скорость реконструкции пикселей является надежной метрикой для сравнения скорости реконструкции. Это средняя скорость на тестовом наборе данных, деленная на 3D-разрешение данных (т.е. общее количество пикселей спектральных данных, используемых для тестирования).
Таблица 3. Параметры спектрального набора данных
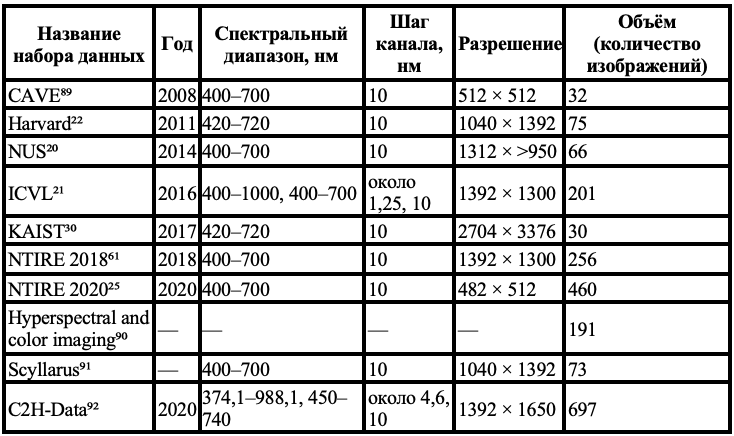
Таблица 4. Описание спектральных наборов данных
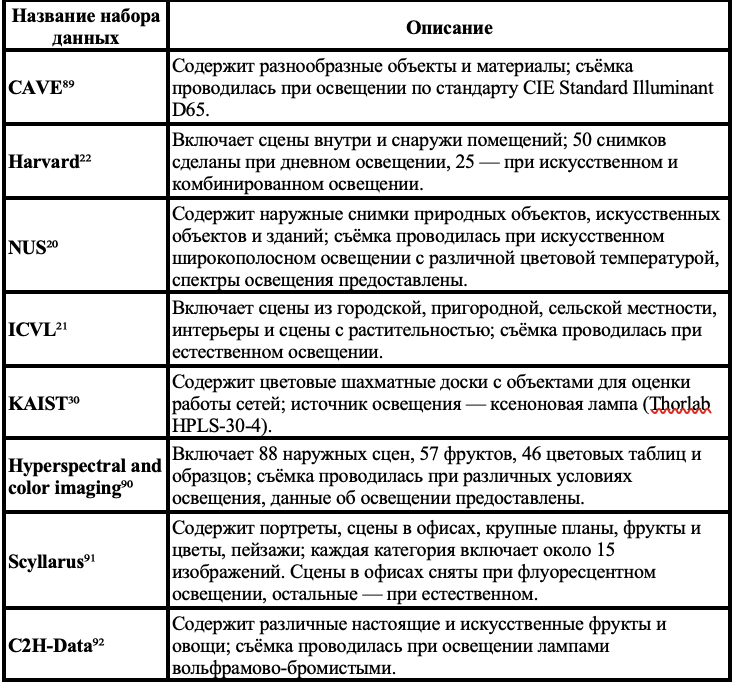
Выводы и направления дальнейших исследований
Мы обобщили различные методы вычислительной реконструкции спектра, в которых используются глубокие нейронные сети, подробно рассмотрев их принципы работы и методы глубокого обучения в рамках трёх модальностей кодирования-декодирования:
1. Кодирование по амплитуде (Amplitude-coded). В этом методе используется кодирующая апертура для амплитудного кодирования — это подход к сжатому спектральному изображению, который опирается на теорию сжатого восприятия и итеративный процесс оптимизации для реконструкции спектра. На основе этой особенности разработаны алгоритмы обучения для сокращения времени, затрачиваемого на оптимизацию (например, развёрнутые сети — unrolled networks), либо используются глубокие нейронные сети для повышения точности оптимизации (например, не обученные сети — untrained networks).
2. Кодирование по фазе (Phase-coded). Здесь для модуляции фазы входящего света для каждой длины волны используется ДОЭ (дифракционная оптическая элемент — DOE). Физически этот метод основан на распространении по Френелю, которое расширяет модуляцию фазы на итоговое изображение. Благодаря творческому подходу к проектированию ДОЭ достигается компактность системы и повышенная пропускная способность света.
3. Кодирование по длине волны (Wavelength-coded). Распространённым примером кодирования по длине волны является RGB-изображение. Преобразование RGB в спектр играет ключевую роль в компьютерной графике, поскольку упрощает настройку сцен со спектрами на мониторах. Для извлечения спектральных характеристик из RGB-данных алгоритмы глубокого обучения либо отображают их в многомерное пространство, либо исследуют внутреннюю пространственно-спектральную корреляцию. В последние годы в качестве расширения подходов на основе RGB разработаны множественные самостоятельно спроектированные широкополосные фильтры для кодирования по длине волны. Этот метод обеспечивает более высокую точность реконструкции спектра, однако результаты также чувствительны к ошибкам изготовления фильтров и шуму при съёмке.
Направления дальнейших исследований
Ожидается, что использование дополнительной информации о сцене повысит точность реконструкции в конкретных прикладных задачах. Например, в системе C2H-Net категория объекта и его положение используются в качестве априорных данных — аналогично известному фреймворку обнаружения объектов YOLO. Было замечено, что фрагменты пикселей с информацией об объекте часто важнее фоновой среды, поэтому эти данные были интегрированы в процесс реконструкции.
Использование дополнительной информации также может повысить эффективность функциональных приложений спектральной съёмки. В последующей работе на основе C2H-Net (ссылка 95) рассматривается задача обнаружения объектов с использованием спектральной съёмки и дополнительных данных об объектах.
Ещё одно важное направление — совместное обучение кодировщика и декодировщика. Кодировщик — это аппаратный уровень, предшествующий алгоритму реконструкции (например, кодирующая апертура, ДОЭ или оптический фильтр). Одновременное обучение кодировщика и декодировщика позволяет передать декодировщику информацию о кодировании, тем самым повышая эффективность работы системы [39, 84].
Однако предстоит решить две проблемы:
1. Поиск более эффективного аппаратного обеспечения для кодирования и интеграция его в слой нейронной сети. Например, можно использовать ДОЭ для повышения пропускной способности света. Также перспективно изучение архитектуры CS-MUSI, способной заменить множество фильтров.
2. Преодоление проблемы исчезновения градиента. Поскольку аппаратный слой является первым слоем всей глубокой нейронной сети, при обратном распространении градиента его значение всегда очень мало. Это ограничивает возможные изменения в аппаратном слое.
Если эти две проблемы будут успешно решены, вычислительная спектральная съёмка с использованием глубокого обучения выйдет на новый уровень.
За последнее десятилетие наблюдался стремительный рост применения глубоких нейронных сетей в спектральной съёмке. Несмотря на успехи глубокого обучения, у него ещё остаётся большой потенциал для дальнейшей оптимизации.
Одним из перспективных методов повышения производительности является обучение с подкреплением (Reinforcement Learning, RL). На сегодняшний день доказано, что RL эффективно использовать для поиска оптимальных архитектур сетей реконструкции — так называемый поиск нейронной архитектуры (Neural Architecture Search, NAS).
С ростом вычислительных мощностей подобные методы обещают значительно повысить эффективность методов спектральной съёмки, основанных на обучении.
Наконец, мы считаем, что глубокие обучающие модели на основе трансформеров (transformer) обладают большим потенциалом для задач реконструкции спектра.
Трансформер — это тип глубокой нейронной сети, первоначально применённый в области обработки естественного языка. В основе трансформера лежит механизм самовнимания (self-attention). Эта архитектура демонстрирует высокие возможности представления данных и широко применяется в задачах компьютерного зрения.
Однако такие крупномасштабные нейронные сети требуют для обучения огромных объёмов данных. Следовательно, необходимы спектральные наборы данных большего объёма, чем когда-либо прежде — как указано в разделе «Наборы данных для спектральной съёмки».
Благодарности
Мы выражаем благодарность доктору Хонгья Сонгу, госпоже Чэннин Тао, госпоже Вэнь Цао и господину Бо Тао из Чжэцзянского университета за ценные обсуждения архитектуры CASSI.
Данная работа была поддержана следующими программами финансирования:
· программа исследований и разработок «Leading Goose» (Чжэцзян) — грант № 2022C01077;
· национальная ключевая программа исследований и разработок Китая — грант № 2018YFA0701400;
· Национальный фонд естественных наук Китая — грант № 92050115;
· Провинциальный фонд естественных наук Чжэцзяна — грант № LZ21F050003.
Сведения об авторах
1. Государственная ключевая лаборатория современных оптических приборов, Колледж оптических наук и технологий, Чжэцзянский университет, Ханчжоу, 310027, Китай.
2. Колледж компьютерных наук и технологий, Чжэцзянский университет, Ханчжоу, 310027, Китай.
3. Ключевая лаборатория фотонного зондирования и интеллектуальной визуализации г. Цзясин, Цзясин, 314000, Китай.
4. Научно-исследовательский центр интеллектуальной оптики и фотоники, Научно-исследовательский институт Чжэцзянского университета в Цзясине, Цзясин, 314000, Китай.
Конфликт интересов
Авторы заявляют об отсутствии конкурирующих интересов.
1. Кодирование по амплитуде (Amplitude-coded). В этом методе используется кодирующая апертура для амплитудного кодирования — это подход к сжатому спектральному изображению, который опирается на теорию сжатого восприятия и итеративный процесс оптимизации для реконструкции спектра. На основе этой особенности разработаны алгоритмы обучения для сокращения времени, затрачиваемого на оптимизацию (например, развёрнутые сети — unrolled networks), либо используются глубокие нейронные сети для повышения точности оптимизации (например, не обученные сети — untrained networks).
2. Кодирование по фазе (Phase-coded). Здесь для модуляции фазы входящего света для каждой длины волны используется ДОЭ (дифракционная оптическая элемент — DOE). Физически этот метод основан на распространении по Френелю, которое расширяет модуляцию фазы на итоговое изображение. Благодаря творческому подходу к проектированию ДОЭ достигается компактность системы и повышенная пропускная способность света.
3. Кодирование по длине волны (Wavelength-coded). Распространённым примером кодирования по длине волны является RGB-изображение. Преобразование RGB в спектр играет ключевую роль в компьютерной графике, поскольку упрощает настройку сцен со спектрами на мониторах. Для извлечения спектральных характеристик из RGB-данных алгоритмы глубокого обучения либо отображают их в многомерное пространство, либо исследуют внутреннюю пространственно-спектральную корреляцию. В последние годы в качестве расширения подходов на основе RGB разработаны множественные самостоятельно спроектированные широкополосные фильтры для кодирования по длине волны. Этот метод обеспечивает более высокую точность реконструкции спектра, однако результаты также чувствительны к ошибкам изготовления фильтров и шуму при съёмке.
Направления дальнейших исследований
Ожидается, что использование дополнительной информации о сцене повысит точность реконструкции в конкретных прикладных задачах. Например, в системе C2H-Net категория объекта и его положение используются в качестве априорных данных — аналогично известному фреймворку обнаружения объектов YOLO. Было замечено, что фрагменты пикселей с информацией об объекте часто важнее фоновой среды, поэтому эти данные были интегрированы в процесс реконструкции.
Использование дополнительной информации также может повысить эффективность функциональных приложений спектральной съёмки. В последующей работе на основе C2H-Net (ссылка 95) рассматривается задача обнаружения объектов с использованием спектральной съёмки и дополнительных данных об объектах.
Ещё одно важное направление — совместное обучение кодировщика и декодировщика. Кодировщик — это аппаратный уровень, предшествующий алгоритму реконструкции (например, кодирующая апертура, ДОЭ или оптический фильтр). Одновременное обучение кодировщика и декодировщика позволяет передать декодировщику информацию о кодировании, тем самым повышая эффективность работы системы [39, 84].
Однако предстоит решить две проблемы:
1. Поиск более эффективного аппаратного обеспечения для кодирования и интеграция его в слой нейронной сети. Например, можно использовать ДОЭ для повышения пропускной способности света. Также перспективно изучение архитектуры CS-MUSI, способной заменить множество фильтров.
2. Преодоление проблемы исчезновения градиента. Поскольку аппаратный слой является первым слоем всей глубокой нейронной сети, при обратном распространении градиента его значение всегда очень мало. Это ограничивает возможные изменения в аппаратном слое.
Если эти две проблемы будут успешно решены, вычислительная спектральная съёмка с использованием глубокого обучения выйдет на новый уровень.
За последнее десятилетие наблюдался стремительный рост применения глубоких нейронных сетей в спектральной съёмке. Несмотря на успехи глубокого обучения, у него ещё остаётся большой потенциал для дальнейшей оптимизации.
Одним из перспективных методов повышения производительности является обучение с подкреплением (Reinforcement Learning, RL). На сегодняшний день доказано, что RL эффективно использовать для поиска оптимальных архитектур сетей реконструкции — так называемый поиск нейронной архитектуры (Neural Architecture Search, NAS).
С ростом вычислительных мощностей подобные методы обещают значительно повысить эффективность методов спектральной съёмки, основанных на обучении.
Наконец, мы считаем, что глубокие обучающие модели на основе трансформеров (transformer) обладают большим потенциалом для задач реконструкции спектра.
Трансформер — это тип глубокой нейронной сети, первоначально применённый в области обработки естественного языка. В основе трансформера лежит механизм самовнимания (self-attention). Эта архитектура демонстрирует высокие возможности представления данных и широко применяется в задачах компьютерного зрения.
Однако такие крупномасштабные нейронные сети требуют для обучения огромных объёмов данных. Следовательно, необходимы спектральные наборы данных большего объёма, чем когда-либо прежде — как указано в разделе «Наборы данных для спектральной съёмки».
Благодарности
Мы выражаем благодарность доктору Хонгья Сонгу, госпоже Чэннин Тао, госпоже Вэнь Цао и господину Бо Тао из Чжэцзянского университета за ценные обсуждения архитектуры CASSI.
Данная работа была поддержана следующими программами финансирования:
· программа исследований и разработок «Leading Goose» (Чжэцзян) — грант № 2022C01077;
· национальная ключевая программа исследований и разработок Китая — грант № 2018YFA0701400;
· Национальный фонд естественных наук Китая — грант № 92050115;
· Провинциальный фонд естественных наук Чжэцзяна — грант № LZ21F050003.
Сведения об авторах
1. Государственная ключевая лаборатория современных оптических приборов, Колледж оптических наук и технологий, Чжэцзянский университет, Ханчжоу, 310027, Китай.
2. Колледж компьютерных наук и технологий, Чжэцзянский университет, Ханчжоу, 310027, Китай.
3. Ключевая лаборатория фотонного зондирования и интеллектуальной визуализации г. Цзясин, Цзясин, 314000, Китай.
4. Научно-исследовательский центр интеллектуальной оптики и фотоники, Научно-исследовательский институт Чжэцзянского университета в Цзясине, Цзясин, 314000, Китай.
Конфликт интересов
Авторы заявляют об отсутствии конкурирующих интересов.
19 февраля / 2026